| 关联规则 | 关联知识 | 关联工具 | 关联文档 | 关联抓包 |
| 参考1(官网) | |
| 参考2 | |
| 参考3 |
用户在浏览网页时会面临各种威胁。用户可能会被诱骗与误导性或虚假网站(也称为网络钓鱼)共享密码等敏感信息。他们还可能被引导在他们的机器上安装恶意软件,称为恶意软件,该软件可以收集个人数据并持有这些数据以勒索赎金。Google Chrome(以下简称 Chrome)使用户能够保护自己免受互联网上的此类威胁。当 Chrome 用户使用安全浏览保护浏览网页时,Chrome 会使用 Google 的安全浏览服务来识别和抵御各种威胁。 [出自:jiwo.org]
安全浏览根据用户的喜好以不同的方式工作。在最常见的情况下,Chrome 使用安全浏览服务中的隐私意识更新 API(应用程序编程接口)。此 API的开发考虑了用户隐私,并确保 Google 尽可能少地获取有关用户浏览历史记录的信息。如果用户选择了"增强保护"(在之前的帖子中介绍过)或"让搜索和浏览更好",Chrome 会与安全浏览共享有限的额外数据,以进一步提高用户保护。
这篇文章描述了 Chrome 是如何实现更新 API 的,适当的指针指向技术实现和更新 API 的隐私意识方面的细节。这对于用户了解安全浏览如何保护他们以及感兴趣的开发人员浏览和了解实现应该很有用。我们将在以后的文章中介绍用于增强保护用户的 API。
互联网上的威胁
当用户导航到 Internet 上的网页时,他们的浏览器会获取托管在 Internet 上的对象。这些对象包括网页的结构 (HTML)、样式 (CSS)、浏览器中的动态行为 (Javascript)、图像、导航启动的下载以及嵌入在主网页中的其他网页。这些对象,也称为资源,有一个称为 URL(统一资源定位器)的网址。此外,URL 在加载时可能会重定向到其他 URL。这些 URL 中的每一个都可能承载网络钓鱼网站、恶意软件、不需要的下载、恶意软件、不公平的计费做法等威胁。具有安全浏览功能的 Chrome 会检查所有 URL、重定向或包含的资源,以识别此类威胁并保护用户。
安全浏览列表
安全浏览为它保护用户免受 Internet 上的每个威胁提供了一个列表。chrome://safe-browsing/#tab-db-manager通过访问桌面平台 可以找到 Chrome 中使用的完整列表目录。
列表不包含完整的不安全网址(也称为 URL);将它们全部保存在设备有限的内存中会非常昂贵。相反,它通过加密散列函数 (SHA-256) 将一个可能很长的 URL 映射到一个唯一的固定大小的字符串。这种不同的固定大小的字符串,称为散列,允许列表有效地存储在有限的内存中。更新 API 仅以哈希的形式处理 URL,在本文中也称为基于哈希的 API。
此外,列表也不会完整地存储散列,因为即使这样也会太占用内存。相反,除非数据不与 Google 共享并且列表很小,否则它包含哈希的前缀。我们将原始散列称为完整散列,将散列前缀称为部分散列。
在更新 API 的请求频率部分之后更新了一个列表。如果响应不成功,Chrome 还会遵循退避模式。这些更新大约每 30 分钟发生一次,遵循服务器在列表更新响应中设置的最短等待时间。
对于那些有兴趣浏览相关源代码的人,这里是看的地方:
源代码
- GetListInfos()包含所有列表,以及它们相关的威胁类型、它们使用的平台以及它们在磁盘上的文件名。
- HashPrefixMap显示了列表是如何存储和维护的。它们按前缀的大小分组,并附加在一起以允许基于二进制搜索的快速查找。
基于哈希的 URL 查找是如何完成的
作为安全浏览列表的示例,假设我们有一个用于恶意软件的列表,其中包含已知托管恶意软件的 URL 的部分哈希值。这些部分散列的长度通常为 4 个字节,但出于说明目的,我们仅显示 2 个字节。
['036b', '1a02', 'bac8', 'bb90']
每当 Chrome 需要使用更新 API 检查资源的信誉时,例如在导航到 URL 时,它不会与安全浏览共享原始 URL(或其中的任何部分)来执行查找。相反,Chrome 使用 URL 的完整哈希(和一些组合)在本地维护的安全浏览列表中查找部分哈希。Chrome 仅将这些匹配的部分哈希发送到安全浏览服务。这可确保 Chrome 在尊重用户隐私的同时提供这些保护。这种基于哈希的查找在 Chrome 中分三个步骤进行:
第 1 步:生成 URL 组合和完整哈希
当 Google 通过将托管潜在不安全资源的 URL 放置在安全浏览列表中来阻止它们时,恶意行为者可以将资源托管在不同的 URL 上。恶意行为者可以循环通过各种子域来生成新的 URL。安全浏览使用主机后缀来识别在其子域中托管恶意软件的恶意域。同样,恶意行为者也可以循环通过各种子路径来生成新的 URL。因此,安全浏览还使用路径前缀来识别在各种子路径中托管恶意软件的网站。这可以防止恶意行为者在子域或路径中循环寻找新的恶意 URL,从而实现强大而有效的威胁识别。
为了合并这些主机后缀和路径前缀,Chrome 首先计算 URL 的完整哈希值以及从 URL 派生的一些模式。按照 Safe Browsing API 的URL 和哈希规范,Chrome 会按照以下步骤计算 URL 组合的完整哈希:
- 首先,Chrome 将 URL 转换为规范中定义的规范格式。
- 然后,Chrome 会为该 URL 生成最多 5 个主机后缀/变体。
- 然后,Chrome 会为 URL 生成多达 6 个路径前缀/变体。
- 然后,对于组合的 30 个主机后缀和路径前缀组合,Chrome 会为每个组合生成完整的哈希值。
源代码
- V4LocalDatabaseManager::CheckBrowseURL是一个执行基于哈希的查找的示例。
- V4ProtocolManagerUtil::UrlToFullHashes为一个 URL 创建各种 URL 组合,并计算它们的完整哈希值。
例子
例如,假设用户正在尝试访问https://evil.example.com/blah#frag. 规范网址是https://evil.example.com/blah. 要尝试的主机后缀是evil.example.com, 和example.com. 路径前缀是/和/blah。四个组合的 URL 组合是evil.example.com/、evil.example.com/blah、example.com/和example.com/blah。
url_combinations = ["evil.example.com/","evil.example.com/blah","example.com/","example.com/blah"] full_hashes = ['1a02...28', 'bb90...9f', '7a9e...67', 'bac8...fa']
步骤 2:在本地列表中搜索部分哈希
然后,Chrome 会根据本地维护的安全浏览列表检查 URL 组合的完整哈希值。这些包含部分哈希的列表不提供决定性的恶意判断,但可以快速识别 URL 是否被认为是非恶意的。如果 URL 的完整哈希与本地列表中的任何部分哈希都不匹配,则认为该 URL 是安全的,Chrome 会继续加载它。超过 99% 的检查 URL 都会发生这种情况。
源代码
- V4LocalDatabaseManager::GetPrefixMatches获取 URL 及其组合的完整哈希的匹配部分哈希。
例子
Chrome 发现三个完整哈希1a02...28、bb90...9f和bac8...fa匹配本地部分哈希。我们注意到这是出于演示目的,这里的匹配很少见。
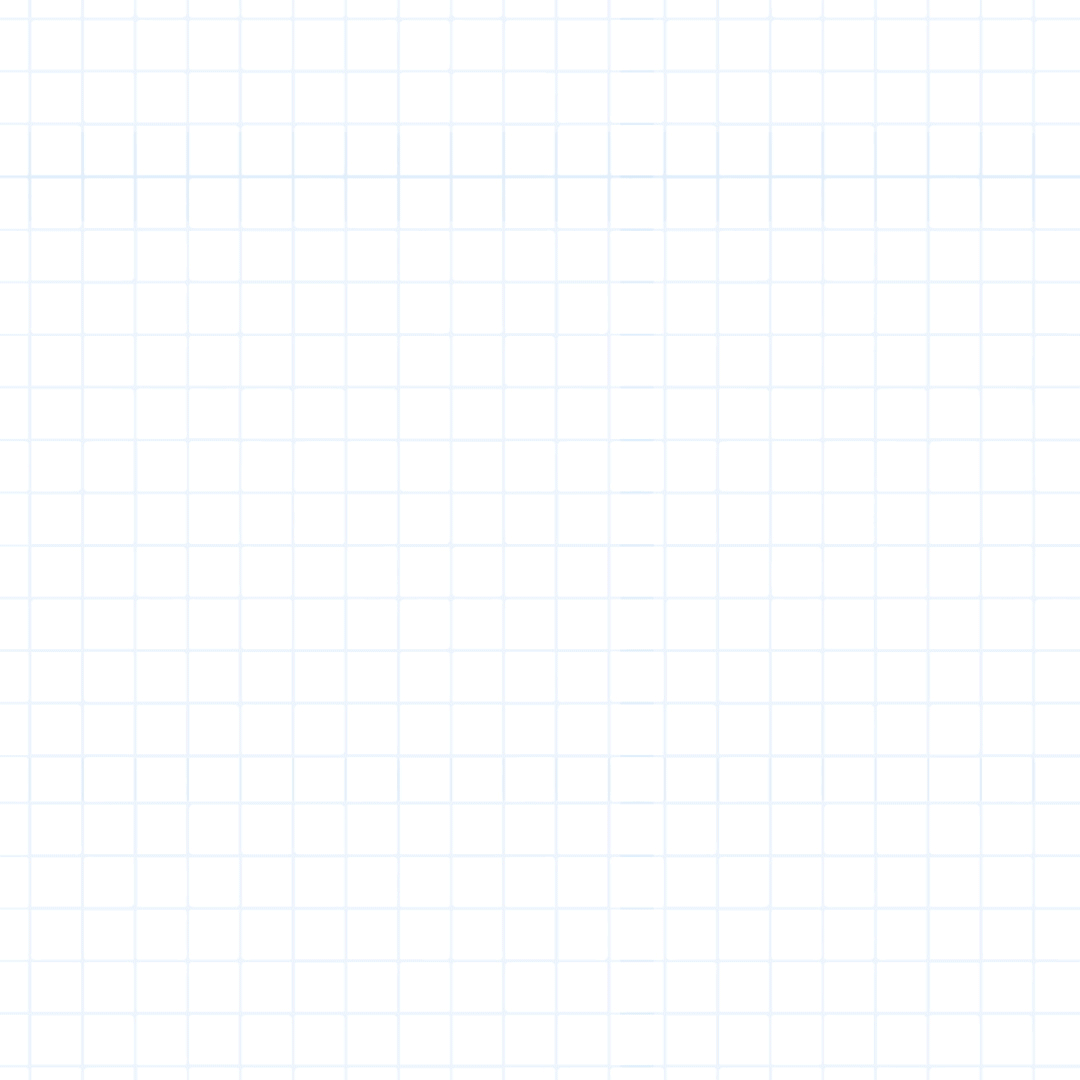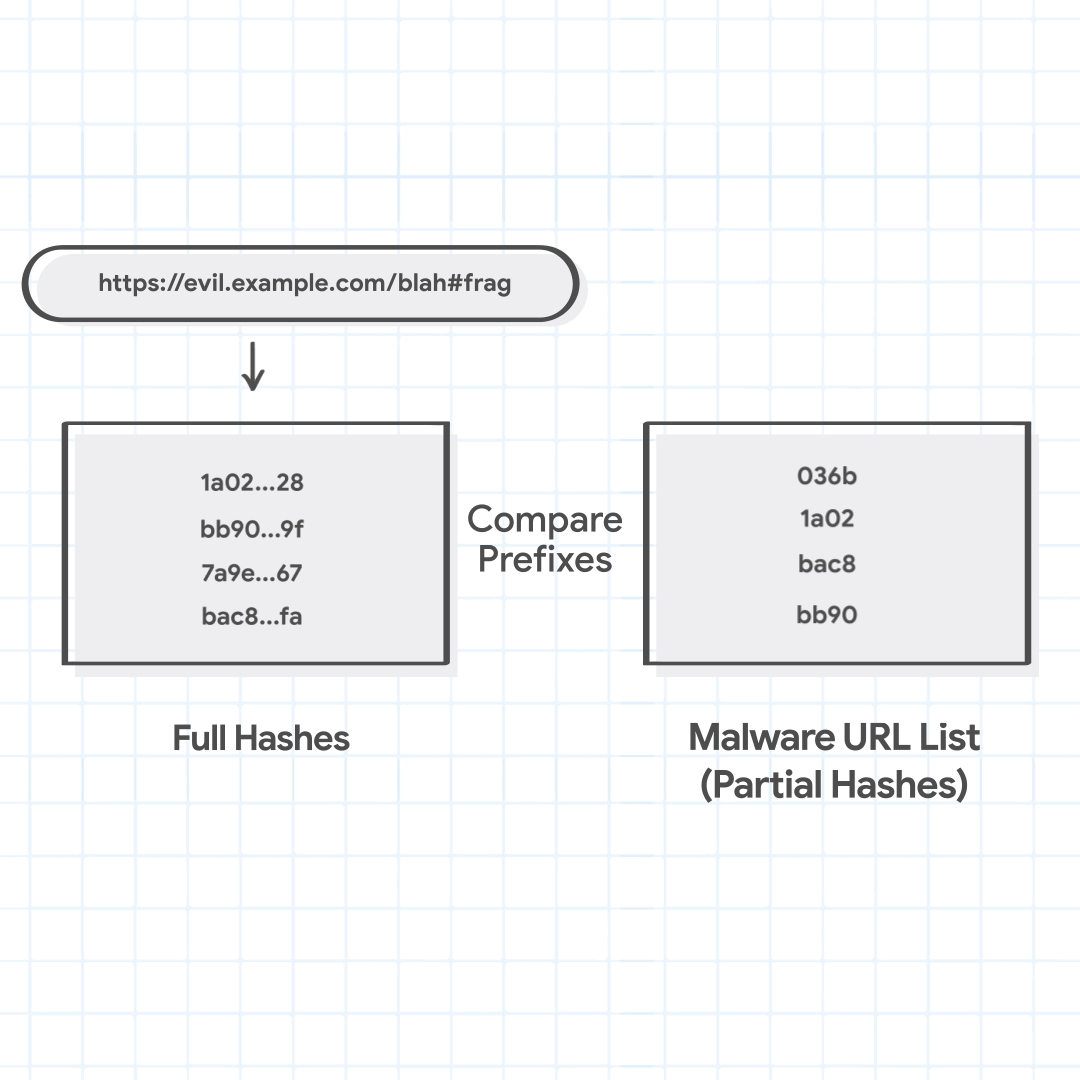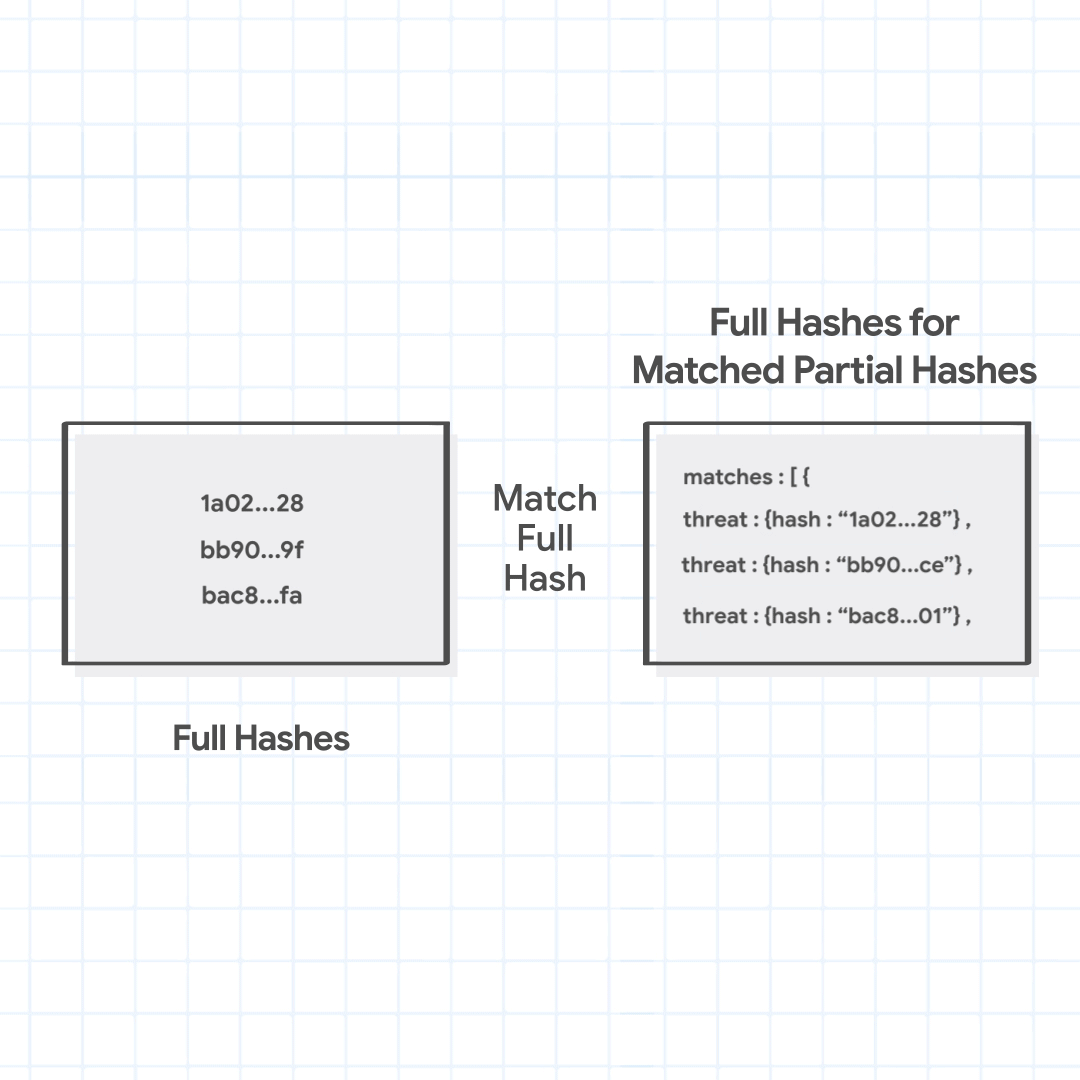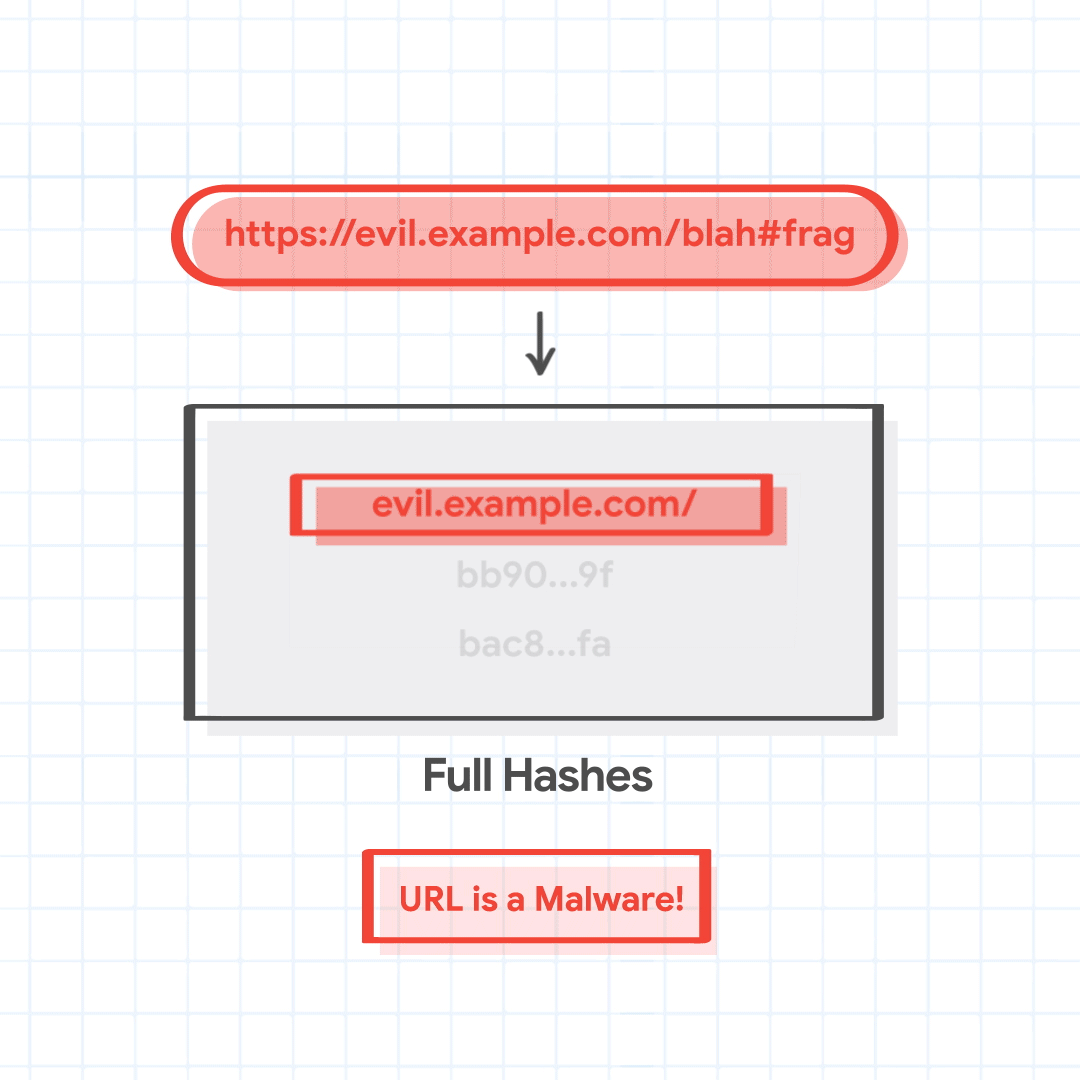
第 3 步:获取匹配的完整哈希
接下来,Chrome仅 将匹配的部分哈希(不是完整的 URL 或 URL 的任何特定部分,甚至它们的完整哈希)发送到安全浏览服务的fullHashes.find方法。作为响应,它会接收所有恶意 URL 的完整散列,其中完整散列以 Chrome 发送的部分散列之一开头。Chrome 使用生成的 URL 组合的完整哈希值检查获取的完整哈希值。如果找到任何匹配项,它会识别具有各种威胁的 URL 及其从匹配的完整哈希中推断出的严重性。
源代码
- V4GetHashProtocolManager::GetFullHashes为匹配的部分散列执行完整散列的查找。
例子
Chrome 发送匹配的部分哈希 1a02、bb90 和 bac8 以获取完整哈希。服务器返回与这些部分哈希匹配的完整哈希,1a02...28, bb90...ce,并且bac8...01. Chrome 发现其中一个完整哈希值与正在检查的 URL 组合的完整哈希值匹配,并将恶意 URL 识别为托管恶意软件。
来源:https://security.googleblog.com/2022/08/how-hash-based-safe-browsing-works-in.html

