| 关联规则 | 关联知识 | 关联工具 | 关联文档 | 关联抓包 |
| 参考1(官网) | |
| 参考2 | |
| 参考3 |
1 前言
攻击日志和溯源流程可从《记一次从后门开展的应急响应溯源》看起,简单分析就是从后门文件“plugins/layer/mobile/need/wwConapp.php”进行溯源,发现攻击者ip为115.238.195.188,后对该ip攻击日志排查,发现攻击者是直接从另一个后门文件“/search/2.php”进入,接着对该文件的历史访问ip进行梳理,最终发现180.126.246.121通过zzzcms的模板注入漏洞进行攻击,从而植入后门。[出自:jiwo.org]
整条溯源方法应该说是比较普遍通用的,那么在实际过程中发现,某些shell可能会经过转手贩卖,导致在溯源过程中会有多个ip访问的干扰问题,针对这种问题,笔者想如果通过建立访问日志图谱,对图谱进行查询,是不是就能达到通过某一个shell节点的图谱遍历,明显的出现某一个ip对多个shell或多个ip对同个shell的访问记录,从而判断哪些是真实攻击者,哪些是疑似黑灰产从业者,甚至真实攻击者的所有操作记录是否存在一些共性的行为,于是便有了此篇。
2 图谱构造
不同于市面上的可视化软件,大部分都是在图谱可视化上下功夫,但是数据架构还是老一套架构,只是借助可视化来展现数据之间的关联。如果从第一步,我们就建立基于access.log的访问日志图谱,是不是就可以直接入手可视化,实现架构上的变化,但是图数据库的可视化功能仍然有限,本文也只是浅尝辄止,如果真的想用于实战分析,后续的js可视化展示还是必须要做的。
由于手里的日志大多是apache的access.log,那么就针对这个中间件的记录模式来做数据抽取
39.98.124.123 - - [25/Apr/2020:00:15:07 +0800] "GET /data/admin/allowurl.txt HTTP/1.1" 404 1706 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0" 157.55.39.182 - - [25/Apr/2020:00:50:18 +0800] "GET /product/?10_33.html HTTP/1.1" 404 1706 "-" "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)" 207.46.13.123 - - [25/Apr/2020:01:02:15 +0800] "GET /upLoad/slide/banner1.jpg HTTP/1.1" 404 1706 "-" "Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)" 106.11.154.126 - - [25/Apr/2020:01:20:13 +0800] "GET /?list/16 HTTP/1.1" 200 10719 "-" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 YisouSpider/5.0 Safari/537.36"
建立图谱,可能不同于mysql或者oracle的架构,得一开始就得把图谱框架搭好,便于后面的遍历和分析,那么这里我们选择需要的信息,如访问ip、访问时间、访问方式、访问URL、返回状态、返回页面长度和UA,这里几乎所有的信息都用到了,避免后面如果想要查询某个信息而访问不到的尴尬境地。
line = line.strip().split(' ') ip , time , method , url ,status , res_length , ua = line[0] , line[3].strip("[") , line[5].strip('"') , line[6].replace('//','/') , line[8] , line[9] , ' '.join(line[11:-1]).strip('"').replace(',','')
那么数据抽取出来,如何进行图谱节点和访问的构建呢?这里笔者其实思考了很久,从访问关系来说,a->b,那么a一定是访问ip,b一定是访问url,这也是最后采取的方式,简单明了,其中a和b的访问关系属性就是访问方式、访问时间等;第二种则是对url节点的构建,在上篇文章,遇到了同目录下不同shell的情况,攻击者为了掩人耳目,可能在一定操作后将原shell更改为另一个shell,导致溯源困难,那么如果对url节点进行进一步解析,如“plugins/layer/mobile/need/wwConapp.php”拆分成“plugins”、“layer”等目录节点和“wwConapp.php”页面节点,那么在展示时是不是就能发现更换替换shell的情况,不过后来考虑到图查询语句本身也有contains这样的断言语句,就未采取“访问ip->网站目录->具体页面”这样的架构。
fp1 = open('ipItem.csv','w') fp1.write(':ID,ip,:LABEL\r\n') fp2 = open('urlItem.csv','w') fp2.write(':ID,url,:LABEL\r\n') fp3 = open('relationship_ip_url.csv','w') fp3.write(':START_ID,time,method,query,res_length,ua,:END_ID,:TYPE\r\n') fp1.write(','.join([md5(ip),ip,'IPITEM'])) fp2.write(','.join([md5(path),path,'URLITEM'])) fp3.write(','.join([md5(ip),time,method,query,res_length,ua,md5(path),status]))
这里对操作日志进行解析,最终写入三个文件,一个是ip的节点文件,一个是url的节点文件,一个是记录访问关系的关系文件,将csv文件导入到neo4j,就已经将访问关系表达出来了
##ipItem.csv :ID,ip,:LABEL ef7c4963c93ddac508eef1025ce5922a,46.229.168.163,IPITEM 76d43e0fe8996a3daf697b0baed1aefd,46.229.168.132,IPITEM ## urlItem.csv :ID,url,:LABEL e624da5a6e37b271147c2d59cfb90ed8,"/robots.txt",URLITEM bc35ab27cca27ebc3823ba53646551a5,"/",URLITEM 8718386cdb80be7b8db75ffa5509c564,"/about/",URLITEM ## relationship_ip_url.csv :START_ID,time,method,query,res_length,ua,:END_ID,:TYPE ef7c4963c93ddac508eef1025ce5922a,29/Jun/2020:00:11:51,GET,"",1706,Mozilla/5.0 (compatible; SemrushBot/6~bl;,e624da5a6e37b271147c2d59cfb90ed8,404 76d43e0fe8996a3daf697b0baed1aefd,29/Jun/2020:00:11:53,GET,"",16016,Mozilla/5.0 (compatible; SemrushBot/6~bl;,bc35ab27cca27ebc3823ba53646551a5,200
最后将建立的node和relationshop导入到neo4j当中,建立采用导入的方式,不要用py2neo去操作,时间差的不是一点半点
./neo4j-import --nodes ~/Desktop/data/ipItem.csv --nodes ~/Desktop/data/urlItem.csv --relationships ~/Desktop/data/relationship_ip_url.csv --into ../data/databases/graph.db

3 图谱查询
既然已经将所有的web访问日志打到了图数据库当中,那么接下来也必须用cypher来进行查询,我偏向用图查询语句来进行溯源,是因为有点类似codeql,cypher其实就已经体现了自己的排查思路和真实存在的访问关系,能够实时展现自己想要的结果。下面就重新笔者的溯源思路,一步步从图中发现问题本质。
3.1 后门访问ip查询
这也是溯源的第一步,对访问后门的ip访问记录进行查询,第一个图查询语句比较直接,就是直接根据后门的url地址,看看谁访问了该后门,但是实际情况是该后门已被重命名,如果这样寻找会发现没有记录,因此为了扩大搜索范围,对同一目录下的文件访问记录也进行查询。
MATCH path=(p:IPITEM)-[r:`200`]->(q:URLITEM) where q.url="/plugins/layer/mobile/need/wwConapp.php" RETURN path
或者
MATCH path=(p:IPITEM)-[r:`200`]->(q:URLITEM) where q.url contains "/plugins/layer/mobile/need" RETURN path

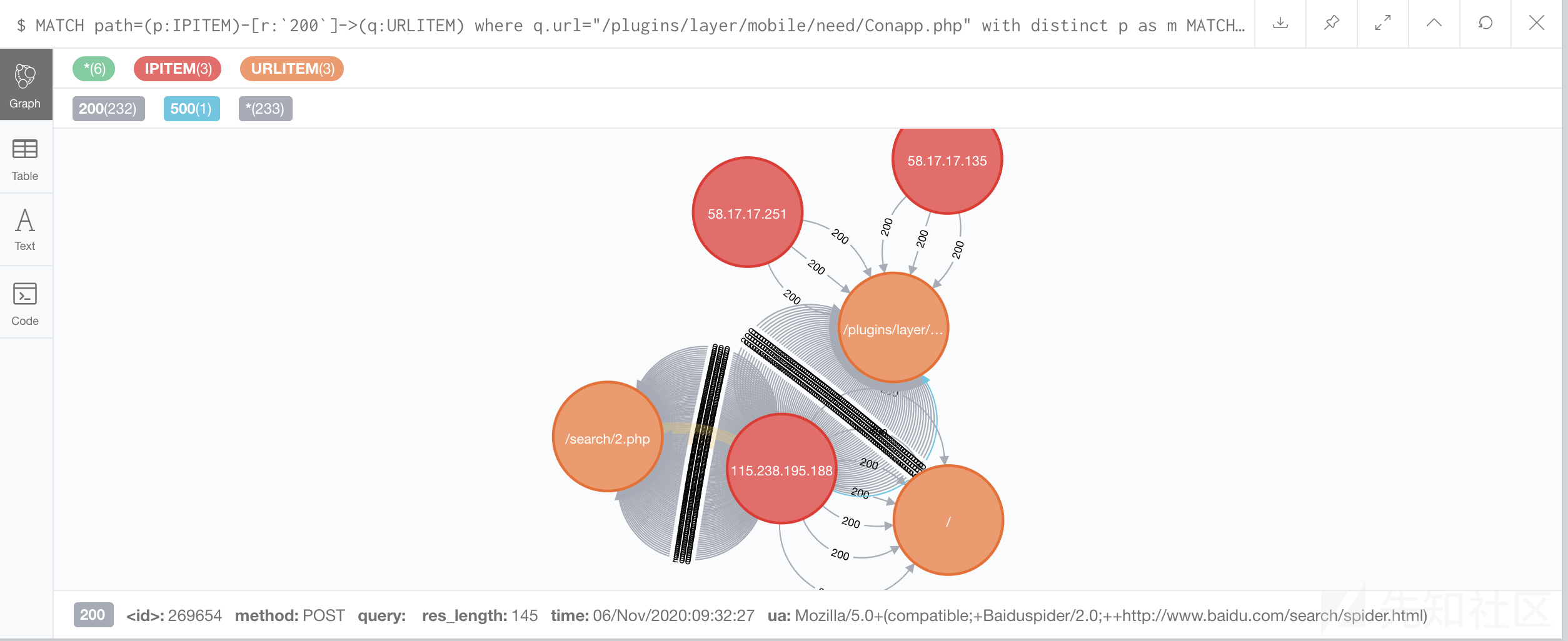
可以发现115.238.195.188这个ip曾对同目录下的Conapp.php进行过大量操作,其余两个ip基本都是蜻蜓点水,没有多余操作,因此将排查重点放到这个115.238.195.188上面
3.2 后门访问ip的所有访问路径
刚才通过初步排查,已经得到了存疑的三个ip,那么接下来我们从后门出发,对这三个ip的所有访问记录进行遍历,由于图查询语句有限,因此在limit的情况下可能会存在数据不全,因此如果想要实战,还是得重新规划可视化界面,将所有数据进行展示,便于分析。
MATCH path=(p:IPITEM)-[r:`200`]->(q:URLITEM) where q.url="/plugins/layer/mobile/need/Conapp.php" with distinct p as m
MATCH path1=(m)-[r:`200`]->(n:URLITEM) where size((m)--(n))>1 return path1 LIMIT 500

到这里可以看到115.238.195.188曾访问过/search/2.php,事实上经过现场排查会发现该文件也是后门文件,到这里可以表示我们的排查思路是朝着正确的方向在走。
3.3 可疑url的所有访问路径
此时,我们溯源的重点应该放到后门文件上,也就是这个/search/2.php上面,因为从访问关系的时间属性来说,可视化上展示的确存在问题,但是点击访问关系可以明显看到该文件的访问时间早于Conapp.php文件
MATCH path=(p:IPITEM)-[r:`200`]->(q:URLITEM) where q.url contains "Conapp.php" with distinct p as m
MATCH path=(m)-[r:`200`]->(n:URLITEM) where size((m)--(n))>1 with distinct n as y
MATCH path=(x:IPITEM)-[r:`200`]->(y:URLITEM) where size((x)--(y))>1 and y.url <>'/' RETURN path limit 500

到这里可以看到越来越多的攻击者ip,其中112.114.100.152这个ip曾大量操作过/search/2.php,从访问时间上也早于115.238.195.188这个ip,因此猜测是更早时间的攻击者
3.4 可疑ip的所有访问路径
其实到这里路子已经打开了,针对疑似ip和疑似后门地址都可以进行遍历,通过图谱展现的方式来对攻击者进行排查溯源
MATCH path=(p:IPITEM)-[r:`200`]->(q:URLITEM) where q.url contains "Conapp.php" with distinct p as m
MATCH path=(m)-[r:`200`]->(n:URLITEM) where size((m)--(n))>1 with distinct n as y
MATCH path=(x:IPITEM)-[r:`200`]->(y:URLITEM) where size((x)--(y))>1 and y.url <>'/' with distinct x as a
MATCH path=(a:IPITEM)-[r:`200`]->(b:URLITEM) where size((a)--(b))>1 return path limit 300
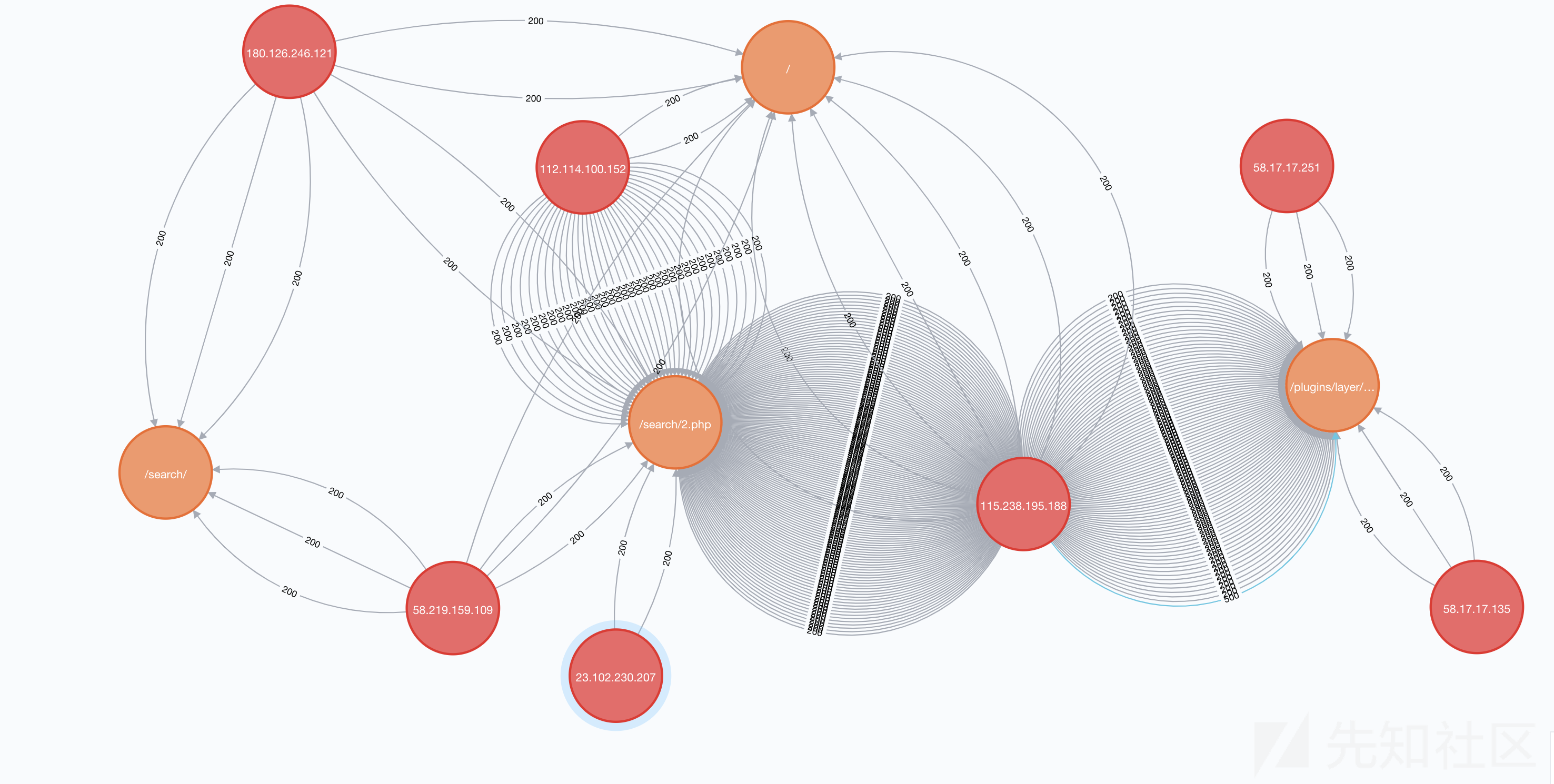
到这里可以看到对search的POST恶意操作,关系属性通过neo4j可以直接展示,所以相对一些GET还是比较明显的,如果也是通过GET语句进行攻击的,那么关系属性通过query来展示,也是可以达到一目了然的目的。
最终180.126.246.121和58.219.159.109都既尝试过模板注入攻击,也访问过遗留下的后门文件,且同一时间都在进行操作,可以将两个ip归为一个团伙。从访问时间来看也没有其他ip比他们更早访问了,因此本次基于图查询的攻击溯源方法还是比较有效的,对这两个ip进行溯源后,发现都是盐城东台电信ip,也更加印证了自己的想法。
4 后记
本文只是用图数据库来做攻击溯源的一次尝试,实际上在分析过程中仅靠图谱来自动化溯源还是有一定难度的,但是既然又能够通过图谱来遍历溯源,又能借助图谱特性来达到攻击可视化的目的,笔者这次探索的效果还是达到了,如果能够再进一步深入,对query语句和url节点进行深层次的挖掘,表达访问目的,如{if:}{endif}就表示为模板注入攻击,将攻击类型直接在访问关系上显示,那么访问路径图就有了更深层次的意义,应该也是未来的发展趋势吧。
上述如有不当之处,敬请指正。

