| 关联规则 | 关联知识 | 关联工具 | 关联文档 | 关联抓包 |
| 参考1(官网) | |
| 参考2 | |
| 参考3 |
数据中毒和后门攻击是通过恶意修改训练数据来操纵受害者的模型。鉴于这种日益严重的威胁,最近对行业专业人士进行的一项调查显示,私营企业对数据中毒的恐惧加剧。以前的很多防毒措施,在面对越来越强的攻击时,要么失效,要么大大降低了性能。然而,我们发现,强大的数据增强功能,如mixup和CutMix,可以在不牺牲性能的情况下显著降低中毒和后门攻击的威胁。我们进一步验证了这种简单的防御方法对自适应中毒方法的有效性,并与包括流行的不同的私人SGD(DP-SGD)防御在内的基线进行了比较。在后门的情况下,CutMix大大减轻了攻击,同时将验证精度提高了9%。 [出自:jiwo.org]
1.导言
机器学习模型已经在许多领域展示了巨大的成效,包括移动图像处理[1]、定向广告投放[2]和安全服务[3]。越来越多的海量数据集有助于最近这种成功。从业者往往依赖于从网络上搜刮的数据或来自第三方的数据[4,5],在这种情况下,这些数据的安全性可能会被恶意行为者破坏。数据中毒攻击构成了一种特殊的威胁,攻击者修改受害者的训练数据,以达到有针对性的错误分类或性能降低等目的。基础的数据中毒方案在训练数据中实现了后门触发,而最近的工作也证明了数据中毒方案可以成功攻击在行业规模数据集上训练的深度学习模型[6,7],而无需进行可感知的修改。这些威胁的严重性得到了行业从业人员的认可,他们最近在一项研究中把中毒列为对其利益最令人担忧的威胁[8]。此外,为较旧的、不那么强大的中毒策略设计的防御措施通过基于特征异常过滤出病毒来工作[9],但当模型在中毒数据上从头开始训练时就会失效[10,7]。目前,唯一能防止最先进的目标中毒的方法是依靠不同的私有SGD(DP-SGD),并将导致验证精度的显著下降[7,11,12]。
另一方面,数据增强一直是从业者的福音,有助于在各种任务上获得最先进的性能[13,14]。数据增强可用于许多制度,包括数据稀疏的环境,以提高泛化能力[15]。简单的增强功能包括随机裁剪或水平翻转。最近,出现了更复杂的增强方案,提高了模型的性能:mixup将随机采样的训练数据进行成对的凸组合,并使用相应的标签凸组合。这不仅可以防止记忆损坏的标签,并提供对对抗性例子的鲁棒性,而且还被证明可以提高泛化能力[13]。另一种增强技术cutout则是随机擦除训练数据的补丁[16],而CutMix则是通过从一幅图像中提取随机补丁,并将这些补丁叠加到其他图像上[17],将一对随机采样的训练数据组合起来。然后将标签按比例混合到这些补丁的面积上。CutMix增强了模型的鲁棒性,实现了更好的测试精度,并通过鼓励网络从局部视图中正确分类图像来提高本地化能力。最后,MaxUp将一组数据增强技术(基础或复杂)应用于训练数据,并选择所有技术中达到模型性能最差的增强方法和参数[14]。通过针对最 “困难 “的数据增强进行训练,MaxUp能够提高泛化能力,在某些情况下,还能提高对抗性鲁棒性。
我们研究了多种增强策略对数据中毒攻击的影响。我们发现,这些现代数据增强策略往往比以往较为繁琐的防毒措施更为有效,同时也不会牺牲显著的自然验证精度。此外,我们的数据增强防御对从业者来说也很方便,因为它只涉及对标准训练管道的微小且易于实施的改变。
我们在简单的后门触发攻击和现代不可感知的目标数据中毒攻击的环境下,对这种防御进行了实证分析[7]。
2.威胁模型
中毒攻击有很多不同的形式。在本文中,我们重点介绍两种来自两方面的攻击:简单有力的后门触发攻击,也是一种现代中毒攻击,针对性强,也是干净的标签。后门触发攻击在训练数据中插入一个特定的触发模式(通常是一个小的补丁,但有时是一个添加干扰或非矩形符号)。如果在测试时再将这个模式添加到图像中,网络将对测试图像进行错误分类,将训练时中毒的训练图像上的标签进行分配。而针对性攻击则是指攻击者希望修改受害者模型,在推理时专门对一组目标图像进行错误分类。这样的攻击通常是干净标签的,这意味着修改后的训练图像保留了它们的语义内容,并被正确标注。这种攻击是基于优化的,利用梯度下降法找到对训练数据最有效的扰动。这使得基于杀毒防御的攻击尤其难以检测,因为它不会显著降低杀毒准确度[6,7]。我们专注于后门和清洁标签攻击,因为它们重新引起了社区的兴趣和最近的兴趣,并且因为它们从两个方面覆盖了中毒文献。
任何中毒威胁模型都可以被正式描述为一个双层问题。设F(x,θ)是一个神经网络,取输入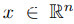 ,参数为
,参数为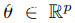 。攻击者可以通过向ith训练图像添加扰动∆i来修改N个总样本中的P个样本(其中P<<N)。对于基于补丁/后门的触发攻击来说,该扰动受到
。攻击者可以通过向ith训练图像添加扰动∆i来修改N个总样本中的P个样本(其中P<<N)。对于基于补丁/后门的触发攻击来说,该扰动受到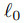 标准的约束,而对于我们考虑的基于优化的攻击来说,则受到
标准的约束,而对于我们考虑的基于优化的攻击来说,则受到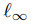 标准的约束。
标准的约束。
攻击者希望通过最小化损失函数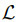 ,找到△,使一组T目标样本
,找到△,使一组T目标样本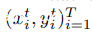 在训练后用新的、不正确的、对抗性的标签
在训练后用新的、不正确的、对抗性的标签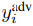 进行分类。
进行分类。
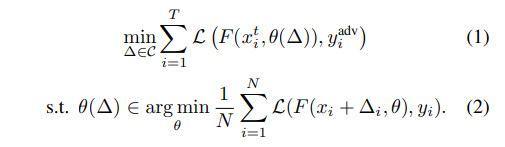
在这个框架中,我们可以将后门攻击理解为根据给定规则直接选择最优的∆(这里通过补丁插入到目标标签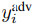 的训练图像上),而基于优化的方法,如[7]则对(棘手的)全二层优化问题的一些近似进行优化。Witches’Brew[7]通过修改训练数据,使训练目标的梯度与对抗损失
的训练图像上),而基于优化的方法,如[7]则对(棘手的)全二层优化问题的一些近似进行优化。Witches’Brew[7]通过修改训练数据,使训练目标的梯度与对抗损失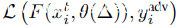 的梯度一致,利用基于对抗文献的优化方法[18,19,20],近似地优化了Δ。
的梯度一致,利用基于对抗文献的优化方法[18,19,20],近似地优化了Δ。
后门攻击和定向数据中毒攻击都依赖于现代深度网络从头开始训练的表现力,以便围绕特定的目标图像 “划分 “网络的决策边界[7]–它们在验证数据上表现正常,而所选择的目标往往被做成一个类离群值,利用不稳定的决策边界以对抗的方式进行外科手术式的标记。因此,我们可以认为训练程序的变化,如强数据增强,可以对决策边界施加规律性,防止目标图像被划分到错误的类别,从而对中毒方法的成功产生重大影响。注意中毒对训练变化的敏感性已经被涉及梯度剪裁/噪声的防御措施所证实,这是唯一在[7,12]中显示出的降低中毒成功率的防御措施。然而,这种防御最终被证明是不切实际的,因为对中毒的鲁棒性带来的自然准确率下降。因此,我们的目标是弥补这一差距,并通过数据增强开发训练中的小变化,在不妨碍正常训练的情况下防御数据中毒。
3.方法
Mixup可以解释为对输入空间中的类区域进行凸化的方法[21]。通过强制将训练点的凸组合分配给标签的凸组合,这种增强方法将类边界规则化,并去除小的非凸区域。特别是,我们的动机是使用混搭来促进去除输入空间中的小 “gerrymandered “区域,其中一个目标/中毒数据实例被分配了一个对抗性标签,同时被具有不同标签的(非中毒)实例包围。
在我们的实验中,我们使用[21]对混合物宽度k的混合过程的泛化,代替Beta分布,凸系数从阶数k的Dirichlet分布Dir[α,……,α]中抽取,插值参数α=1。
我们实现CutMix[22]如下:让D=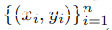 是带有
是带有 的训练数据集。让(xi, yi)和(xj , yj )是两个随机采样的特征-目标对。我们随机生成一个方框
的训练数据集。让(xi, yi)和(xj , yj )是两个随机采样的特征-目标对。我们随机生成一个方框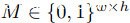 ,表示要切割/粘贴的像素。除了在以(rx, ry)为中心的盒子中它们为零之外,所有M的值都被定义为1。为了获得箱体的位置,我们分别以第一轴和第二轴为中心随机取样 rx ∼ Unif(0,w)和 ry ∼ Unif(0,h)。如同混叠一样,我们使用一个系数
,表示要切割/粘贴的像素。除了在以(rx, ry)为中心的盒子中它们为零之外,所有M的值都被定义为1。为了获得箱体的位置,我们分别以第一轴和第二轴为中心随机取样 rx ∼ Unif(0,w)和 ry ∼ Unif(0,h)。如同混叠一样,我们使用一个系数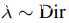 [1,1]来确定两个随机采样数据点的相对贡献,即
[1,1]来确定两个随机采样数据点的相对贡献,即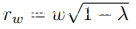 和
和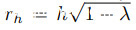 给出M中零点的补丁的宽度和高度。CutMix的增强图像变成
给出M中零点的补丁的宽度和高度。CutMix的增强图像变成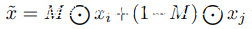 与标签
与标签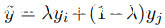 按M的大小比例混合初始标签得到。二进制操作
按M的大小比例混合初始标签得到。二进制操作 表示按元素进行的乘法。切口类似,但贴片仍为黑色。剪切数据点由
表示按元素进行的乘法。切口类似,但贴片仍为黑色。剪切数据点由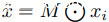 与标签yi给出。
与标签yi给出。
MaxUp的程序取自[14]:对于原始训练集 中的每个数据点xi,会产生一组
中的每个数据点xi,会产生一组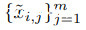 的增强数据点。学习是根据修改后的ERM来定义的,
的增强数据点。学习是根据修改后的ERM来定义的,

4.经验
4.1. 防范后门触发攻击
我们首先证明了数据增强在减轻后门攻击的同时提高测试精度的有效性。为了建立后门攻击的基线,我们在CIFAR-10数据集上训练了一个ResNet-18[23],该数据集由10个平衡类的50000张图像组成[24]。我们通过在随机选择的目标类的训练图像中添加4×4个补丁,将触发器插入训练集。然后,我们从一个新的基类中对打过补丁的图像进行评估,看看补丁是否会触发图像被误分类到目标类中。我们在两种不同的环境下进行这个实验:当所有的训练图像都在基类中进行修补,而只有10%的训练图像在本类中进行修补。这两种情况反映了对手对受害者的训练数据可能有不同的访问权限。
我们在表1中报告了这种攻击在导致基础图像与目标标签错误分类方面的成效。虽然混搭数据增强无法防御后门攻击,但CutMix将中毒攻击的成功率从100%大幅降低到36%,同时将验证精度提高了9%。对于该域中mixup无效的一种解释是,在这种策略下,基类仍然可以与补丁关联。另一方面,CutMix会随机替换部分图像,因此可能会将补丁割开。此外,CutMix提高了杀毒验证精度,因为网络从目标类中学习相关特征,而不是简单地依赖补丁。


4.2. 防范有针对性的中毒攻击
我们现在评估数据增强作为防御定向中毒攻击的方法。为此,我们使用了最先进的方法Witches’ Brew[7],以及一个 “自适应攻击 “的版本,其中攻击是在与受害者相同的数据增强训练的网络上生成的。我们在CIFAR-10上训练了一个ResNet-18,我们考虑的威胁模型的 边界为16/255,预算为1%。对于所有实验,我们考虑用随机水平翻转和随机作物训练的基线模型。然后,我们将现代数据增强与基于差分隐私的防御措施进行比较,特别关注实际的杀毒验证精度,即模型的 “正常 “可用性。我们实施以及平均成功率超过了20次,每次运行由随机选择的目标图像和随机选择的对抗性标签组成。在每次运行中,都会在中毒的训练集上从头开始训练一个新的模型,并在目标图像上进行评估。攻击的成功率越低,防御越有效。
边界为16/255,预算为1%。对于所有实验,我们考虑用随机水平翻转和随机作物训练的基线模型。然后,我们将现代数据增强与基于差分隐私的防御措施进行比较,特别关注实际的杀毒验证精度,即模型的 “正常 “可用性。我们实施以及平均成功率超过了20次,每次运行由随机选择的目标图像和随机选择的对抗性标签组成。在每次运行中,都会在中毒的训练集上从头开始训练一个新的模型,并在目标图像上进行评估。攻击的成功率越低,防御越有效。
表2显示,我们可以使用差异化私有SGD(DP-SGD)[25]进行防御,在所有训练梯度中加入足够量的高斯噪声–但这在验证精度上要付出巨大的代价。在这种基于优化的攻击环境下,我们还必须面对另一个因素:自适应攻击。自适应攻击威胁模型假设攻击者意识到了防御,并且可以根据这个防御优化他们的攻击w.r.t。表2第二栏突出了这种攻击。在这项工作中,我们通过将数据增强纳入攻击中使用的杀毒模型的训练阶段,使WitchesBrew适应高级数据增强。这样一来,中毒数据就会基于一个训练成对这些增量不变的模型来创建。我们通过直通估计来适应[7]中的差分隐私,发现它被自适应攻击缓解得特别好。
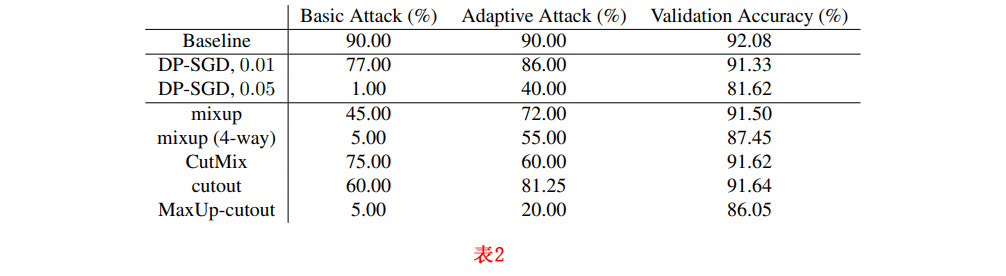
与DP-SGD防御所招致的验证精度损失相比,通过数据增强的防御(表2中的下行,图3中的蓝点)几乎没有验证精度损失。尽管如此,它们还是减少了中毒的成功率,例如,在MaxUp基于四个切口的情况下,最多可减少60%。这一改进支持了[14]的结论,即MaxUp隐含了梯度惩罚,从而平滑了决策边界。另外值得注意的是,对于这种基于优化的中毒攻击案例,在尝试过的那些不会降低验证精度的数据增强方式中,混淆似乎是最优的。我们猜测,这是由于混杂优化在数据点之间强制执行的隐性线性,这使得中毒方案很难成功产生异常值。我们甚至可以通过考虑四倍的图像混合,而不是[21]中讨论的两倍混合,来进一步提高混合的防御能力。在这两种情况下,这种防御甚至比vanilla混合更强,但图像的四倍混合导致数据修改如此明显,以至于它们对验证准确性产生负面影响。
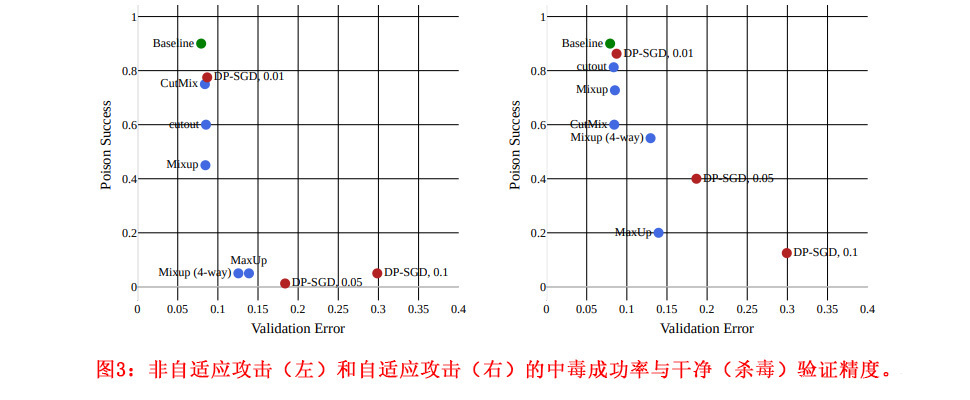
与后门触发攻击相比,CutMix对非自适应攻击的效果较差。不过,我们也发现,对于自适应设置,CutMix在混淆上有所改进。这可能是因为当使用混合时,整个图像都出现在混合图像中,从而使可靠的中毒成为可能。相反,对CutMix的自适应攻击不能先验地知道切割补丁的位置,因此即使知道使用了CutMix,攻击也会受到阻碍。
5.结论
数据中毒攻击对机器学习从业者的威胁越来越大。大体上,防御措施没有跟上快速改进的攻击,这些防御措施的实施可能不切实际。我们证明,现代数据增强方案可以调整神经网络的训练行为,以减轻从头开始的中毒,同时对后门触发和基于优化的攻击保持自然的准确性。我们认为这些结果表明,有可能为病毒防御专门设计增强剂,我们认为这可能是未来研究的一个富有成效的方向。
6.参考文献
[1]Eli Schwartz, Raja Giryes, and Alex M. Bronstein, “Deepisp: Towardlearning an end-to-end image processing pipeline,” IEEE Transactions onImage Processing, vol. 28, no. 2, pp. 912–923, Feb 2019.
下略

