| 关联规则 | 关联知识 | 关联工具 | 关联文档 | 关联抓包 |
| 参考1(官网) | |
| 参考2 | |
| 参考3 |
静态扫描就是不运行程序,通过扫描源代码的方式检查漏洞,常见的方法也有多种,如把源代码生成 AST(抽象语法树)后对 AST 进行分析,找出用户可控变量的使用过程是否流入到了危险函数,从而定位出漏洞;或者通过正则规则来匹配源代码,根据平常容易产生漏洞的代码定制出规则,把这些规则代入到代码中进行验证来定位漏洞。当然静态扫描由于不运行程序也有好多事情处理不了,如程序通过运算得到的一个结果后,就没办法分析这个结果了,所以需要动态运行程序来解决这个问题,也就是动态扫描,动态扫描可以通过单元测试或人工扫描等方式,下面分别介绍一下 AST 扫描 与 正则匹配两种常见静态扫描方式。
AST(抽象语法树)扫描
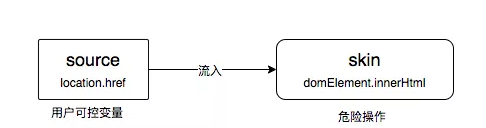
此方式把源码生成 AST(抽象语法树),找出用户可控的 source (如location.href,document.url,document.documentURI) 是否流入到了敏感的 sink (如evil,new function,setTImeout,setInterval) 中,常见的 source 与 sink 可参考这个文档:
https://docs.google.com/spreadsheets/d/1Mnuqkbs9L-s3QpQtUrOkPx6t5dR3QyQo24kCVYQy7YY/edit#gid=0。
扫描程序负责把所有的 source 与 sink 查找出来,并找出 source 已流入到了 sink 中的代码已及行号,并存入到结果中,举个例子:
document.getElement('girl').innerHTML = location.href.split(#)[1]
这句代码命中了 source 流入到了敏感 sink 中,从而产生了漏洞,也很明显能看出产生了 domXss,不过在实际情况中更加复杂,如把 source 当成了函数参数,经过了多个函数处理,扫描程序就需要跟踪这些这种流入到不同的函数中的情况。
正则匹配
这种方式比较简单,就是匹配程序中是否出现了哪些敏感字符,如 bodyParse()或者敏感代码,当函数中的代码命中了设置的规则,则就产生了漏洞,举个例子
(.readFile()(.{0,40000})(req.|req.query|req.body|req.param)
上面是一条正则规则,当函数中有一行代码为fs.readFile('/etc/'+req.param.path),则命中了规则并报出有漏洞。
Javascript 扫描工具介绍
下面分别介绍两款工具,jsprime和NodeJSScan的介绍与实现原理,其中jsprime是通过分析 AST 扫描,NodeJSScan是通过正则表达式扫描。
jsprime
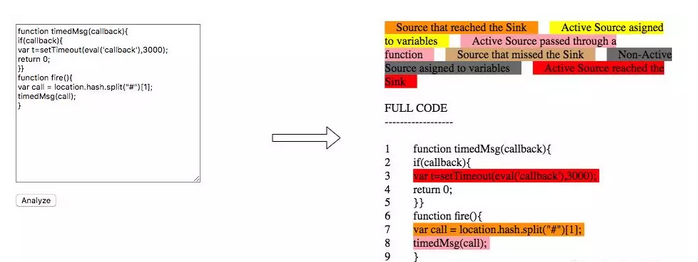 [出自:jiwo.org]
[出自:jiwo.org]
效果图,左边是源码,右边是分析结果
jsprime 是一个静态代码分析工具,其核心是基于 Esprima ECMAScript 生成 AST 进行扫描,此工具有在 blackhat 上演讲过,他的主要功能有:
https://www.slideshare.net/nishantdp/jsprime-bhusa13new
1、JS 库 source 与 sink 识别
2、JQuery 及 YUI 框架识别
3、变量与函数追踪(这项功能作为我们代码流分析算法的组成部分)。
4、变量与函数内容识别分析(这项功能作为我们代码流分析算法的组成部分)。
5、已知过滤器功能识别。
6、遵循面向对象程序与原型设计合规标准。
7、最大程度降低误报机率。
8、支持 JavaScript 代码精简。
9、极高运行速度。
10、只需点击即可操作.
JSPrime 是怎么工作的?
1、把源代码喂给 Esprime,Esprime 负责把代码生成 AST。
2、接下来就是解析 JSON AST(Esprime 会生成 JSON 格式的 AST)。
3、找出所有的 sources(包括 对象,原型) ,同时跟踪 sources 的作用范围。
4、找出 sources 别名,也就是把 soruce 值赋值给了另一变量,同时跟踪 sources 的作用范围。
5、找出 sinks 和 sinks 别名,同时跟踪他们的作用范围。
6、找出 sources 被哪些函数当成参数使用,包括闭包函数、匿名函数,同时跟踪他们的返回值。
7、当所有的 sources 和 source 别名被收集,检查其中的 source 有过滤函数处理了的,则放弃。
8、剩下的 source 当被赋值给 sinks 或被传递为参数操作后到达 sinks 的,则跟踪这些 source。
9、以同样的流程,按照反向重复一次,以确认我们可以反向到达同一个 source。
10、一旦确认 source 流入到了 sink 中,则取出行号和语句,然后以不同颜色输出到报表中。
使用方法
1、下载源码:
http://dpnishant.github.io/jsprime/
2、解压进入到 jsprime-node 文件夹
3、node server.js
4、打开 http://localhost:8888
5、把代码贴到框中进行分析
6、有一些测试代码,可参考:
https://docs.google.com/document/d/17J2h43WbPX3sNTIjxr4GhzEGxKy6hvQJqedd3UQ11mY/edit
参考文档
jsprime-blackhatusa13new:
https://www.slideshare.net/nishantdp/jsprime-bhusa13new
DOM XSS Sources & sinks:
https://docs.google.com/spreadsheets/d/1Mnuqkbs9L-s3QpQtUrOkPx6t5dR3QyQo24kCVYQy7YY/edit
ra2-dom-xss-scanner:
https://code.google.com/archive/p/ra2-dom-xss-scanner/
NodeJSScan

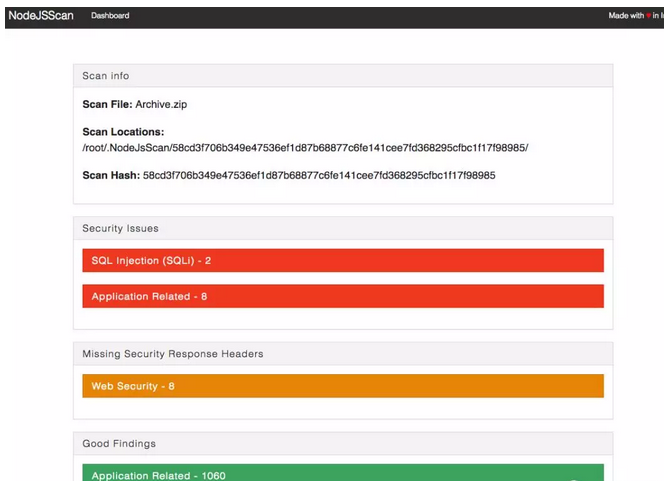
NodeJSScan 是一套用 python 实现的 node 应用代码扫描器,他的原理是通过正则表达式来匹配源码文件中的每一行,每个正则表达式都代表一种漏洞扫描规则,如是否使用了 url 中的值当成 readFile 函数参数,把这些规则用来检查代码中的每一行,一旦匹配则就说明有漏洞。
举个例子:
(.readFile()(.{0,40000})(req.|req.query|req.body|req.param)
这是一条正则表达式,当代码中存在类似readFile("/etc/"+req.param.path)的代码就命中了上面的规则,从而报出有漏洞。
NodeJSSCan 实现原理
1、用户把代码打包成一个 zip 包并上传,服务端解压这个包
2、迭代每一个文件(有文件夹则递归)把读出文件内容
3、文件内容通过 jsbeautify 格式化,并把注释去掉
4、迭代每一行,把代码代入设置的规则中(正则,或字符串查找),当匹配了,则记录起来
6、把匹配规则的代码行按类别存放,如 rce,xss,ssrf,sqli
7、生成结果报

